Spark Performance Optimization: Resource Tuning
After developing the Spark job, you should configure the appropriate resources for the job. Spark resource parameters, the basic can be in the spark-submit command as a parameter set. Many Spark
beginners, usually do not know what the necessary parameters to set,
and how to set these parameters, and finally can only set up random, or
even simply do not set.
Resource settings unreasonable, may lead to the full use of cluster
resources, the operation will be extremely slow; or set the resources
are too large, the queue does not have enough resources to provide,
resulting in a variety of exceptions.
In short, no matter what the situation, will lead to Spark operation of
the operating efficiency is low, or even simply can not run.
So we have to have a clear understanding of the principles of resource
usage for Spark operations and know which resource parameters can be set
during the Spark job run and how to set the appropriate parameter
values.
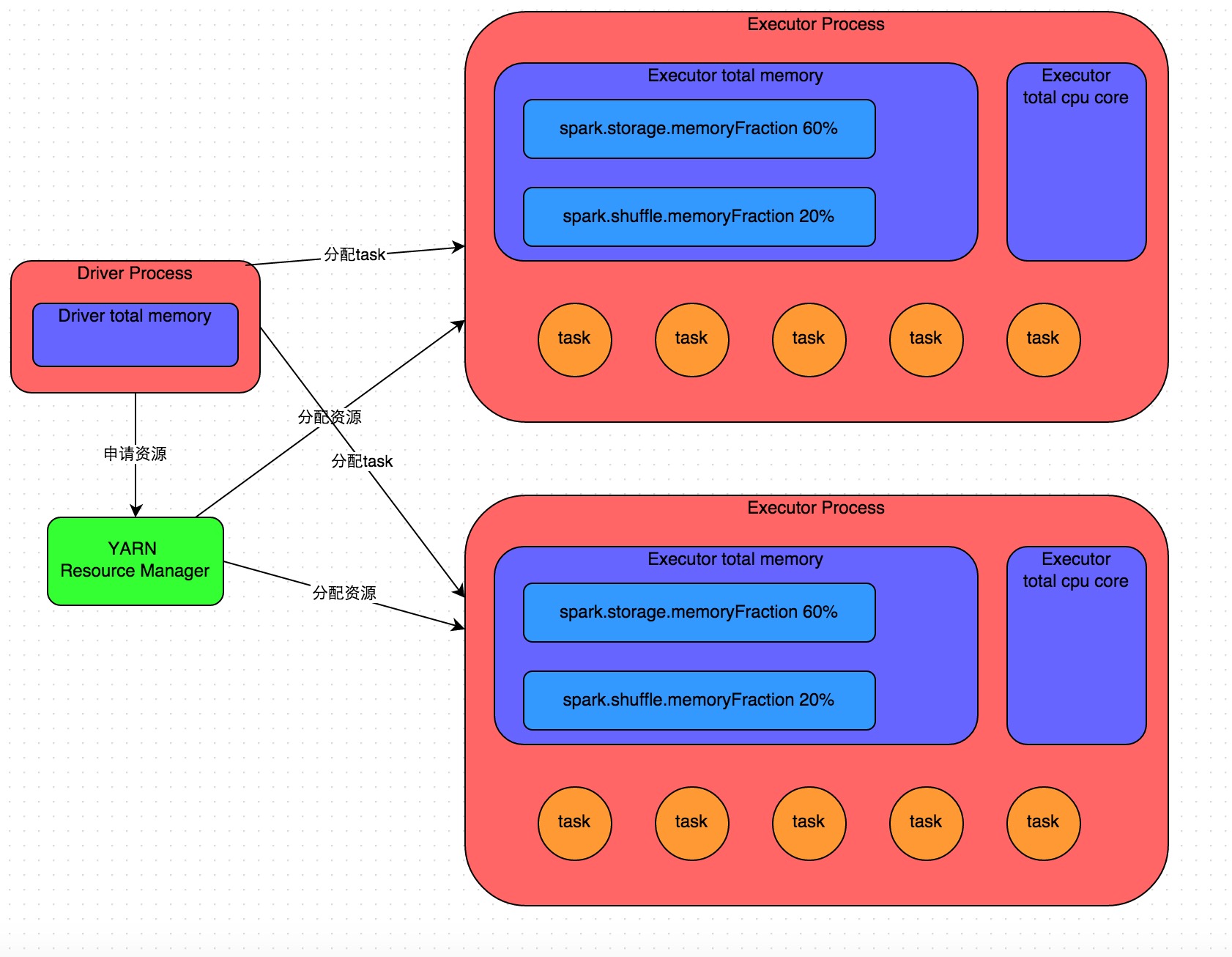 Details of the principle see above. After we submit a Spark job using spark-submit, the job will start a corresponding Driver process. Depending on the deployment mode you are using, the Driver process may be started locally or on a working node in the cluster. Driver process itself will be based on our set of parameters, possession of a certain amount of memory and CPU core.
The first thing to do with the Driver process is to apply to the
cluster manager (which can be a Spark Standalone cluster, or other
resource management cluster, which is used by YARN as a resource
management cluster) to run a Spark job Need to use the resources, where
the resources refer to the Executor process.
YARN Cluster Manager will be based on our resources for the Spark job
parameters, in the various work nodes, start a certain number of
Executor process, each Executor process has a certain amount of memory
and CPU core.
Details of the principle see above. After we submit a Spark job using spark-submit, the job will start a corresponding Driver process. Depending on the deployment mode you are using, the Driver process may be started locally or on a working node in the cluster. Driver process itself will be based on our set of parameters, possession of a certain amount of memory and CPU core.
The first thing to do with the Driver process is to apply to the
cluster manager (which can be a Spark Standalone cluster, or other
resource management cluster, which is used by YARN as a resource
management cluster) to run a Spark job Need to use the resources, where
the resources refer to the Executor process.
YARN Cluster Manager will be based on our resources for the Spark job
parameters, in the various work nodes, start a certain number of
Executor process, each Executor process has a certain amount of memory
and CPU core.
After applying for the resources required for the execution of the job, the Driver process will begin scheduling and executing the job code we have written. Driver process will be prepared by our Spark job code split into multiple stages, each stage to perform part of the code snippet, and for each stage to create a number of tasks, and then these tasks assigned to the implementation of the various Executor process. Task is the smallest unit of computing, is responsible for the implementation of exactly the same computing logic (that is, we write a code fragment), but each task to deal with the data is different. After all the tasks of a stage are executed, the intermediate result will be written in the local disk file of each node, and then the driver will schedule the next stage to be run. The next stage of the task input data is the result of a stage output on the middle. So the cycle, until we write all the logic of the implementation of all the logic, and calculate all the data, we want the results so far.
Spark is based on shuffle class operator to stage the division. If we execute a shuffle class operator (such as reduceByKey, join, etc.) in our code, we will divide the stage boundary at that operator. Can be roughly understood as, shuffle operator before the implementation of the code will be divided into a stage, shuffle operator implementation and after the code will be divided into the next stage. So a stage just started when it's every task may be from a stage of the task where the node, go through the network transmission to extract all the keys to deal with their own, and then pull all the same key to use We write our own functions to perform aggregate operations (such as the function that the reduceByKey () operator receives). This process is shuffle.
When we execute cache / persist and other persistence operations in the code, the data calculated by each task is saved to the memory of the Executor process or the disk file of the node, depending on the persistence level we choose.
So Executor's memory is divided into three: the first piece is to let the implementation of our own code to use the code, the default is 20% of the total memory of the executive; the second is to let the task through the shuffle process to pull a stage The output of the task, the aggregation and other operations used, the default is also accounted for Executive% of the total memory 20%; third is to use RDD persistence, the default accounted for 60% of executive memory.
Task execution speed is with each Executor process CPU core number is directly related. A CPU core at the same time can only perform a thread. And each Executor process assigned to the multiple tasks, are each way a thread of the way, multi-threaded concurrent operation. If the CPU core number is more adequate, and assigned to the number of tasks more reasonable, then usually speaking, you can more quickly and efficiently perform these task threads.
The above is the basic operating principle of Spark operating instructions, we can combine the map to understand. Understand the basic principles of operation, we are the basic premise of resource parameter tuning.
Num-executors
Parameter Description: This parameter is used to set the Spark job to use a total of how many Executor process to perform. Driver When applying for resources to the YARN Cluster Manager, the YARN Cluster Manager will, as far as possible, start the corresponding number of Executor processes on the various work nodes of the cluster. This parameter is very important, if not set, then the default will only give you start a small amount of Executor process, this time your Spark operation is very slow.
Parameter tuning recommendations : the operation of each Spark generally set 50 ~ 100 or so Executor process more appropriate, set too little or too many Executor process is not good. Set too little, can not make full use of cluster resources; set too much, most of the queue may not be able to give sufficient resources.
Executor-memory
Parameter Description: This parameter is used to set the memory of each Executor process. Executor memory size, often directly determine the performance of the Spark job, but also with the common JVM OOM exception, there are direct correlation.
Parameter tuning recommendations : each Executor process memory settings 4G ~ 8G more appropriate. But this is only a reference value, the specific settings or according to the different departments of the resource queue to set. You can see their team's resource queue is the largest memory limit, num-executors multiplied by executor-memory, on behalf of your Spark job application to the total amount of memory (that is, all the memory of all Executor process), the amount Is the maximum amount of memory that can not exceed the queue. In addition, if you are sharing this resource queue with someone else on the team, the total amount of memory applied is best not to exceed the 1/3 to 1/2 of the maximum total memory of the resource queue, avoiding your own Spark jobs taking the queue Resources, leading to other students can not run the homework.
Executor-cores
Parameter Description: This parameter is used to set the number of CPU cores for each Executor process. This parameter determines the ability of each Executor process to execute the task thread in parallel. Because each CPU core at the same time can only perform a task thread, so each Executor process CPU core number more, the more able to quickly complete the distribution of all their own task thread.
Parameter tuning recommendations : Executor CPU core number set to 2 to 4 more appropriate. The same according to the different departments of the resource queue to set, you can look at their own resource queue maximum CPU core limit is how much, and then set the number of Executor to determine each Executor process can be assigned to several CPU core. The same proposal, if it is shared with others to the queue, then num-executors * executor-cores do not exceed the total CPU core 1/3 ~ 1/2 or so more appropriate, but also to avoid affecting the operation of other students.
Driver-memory
Parameter Description : This parameter is used to set the memory of the Driver process.
Parameter tuning recommendations : Driver's memory is usually not set, or set about 1G should be enough. The only thing to note is that if you need to use the collect operator to extract all the RDD data to the driver for processing, you must ensure that the driver's memory is large enough, otherwise there will be OOM memory overflow problem.
Spark.default.parallelism
Parameter Description: This parameter is used to set the default number of tasks per stage. This parameter is extremely important, if not set may directly affect your Spark job performance.
Parameter tuning recommendations : Spark job default task number of 500 to 1000 is more appropriate. Many students often make a mistake is not to set this parameter, then this will lead to Spark own HDFS based on the number of blocks to set the number of tasks, the default is a HDFS block corresponding to a task. In general, the number of Spark default settings is too small (for example, dozens of tasks), if the number of tasks less than the case, it will lead you in front of the parameters of the Executor are exhausted. Imagine, no matter how many of your Executor process, memory and CPU how much, but the task is only one or 10, then 90% of the Executor process may not have the task implementation, that is wasted resources! So Spark official website suggested that the principle is to set the parameters for the num-executors * executor-cores 2 to 3 times more appropriate, such as the total number of CPU master CPU total of 300, then set 1000 task is possible, this time Can take full advantage of Spark cluster resources.
Spark.storage.memoryFraction
Parameter Description: This parameter is used to set the RDD persistent data in the Executor memory can account for the proportion of the default is 0.6. In other words, the default Executor 60% of the memory, can be used to save the persistent RDD data. Depending on the different persistence policy you choose, if the memory is not enough, the data may not be persistent, or the data will be written to disk.
Parameter tuning recommendations : If the Spark operation, there are more RDD persistence operation, the value of the parameter can be appropriately improved to ensure that the persistent data can be accommodated in memory. To avoid the memory is not enough to cache all the data, resulting in data can only be written to disk, reducing performance. But if the Spark operation shuffle class operation is more, and the persistence operation is relatively small, then the value of this parameter is appropriate to reduce some of the more appropriate. In addition, if you find that the operation due to frequent gc slow operation (through the spark web ui can be observed that the operating gc time-consuming), means that the implementation of the user code memory is not enough, then the same proposal to reduce the value of this parameter.
Spark.shuffle.memoryFraction
Parameter Description: This parameter is used to set the shuffle process in a task pull to the output of the last stage of the task, the aggregation operation can be used when the proportion of Executor memory, the default is 0.2. In other words, Executor defaults only 20% of the memory used to carry out the operation. Shuffle operation In the polymerization, if you find the use of memory beyond the 20% of the restrictions, then the excess data will be written to the disk file, this time will greatly reduce performance.
Parameter tuning recommendations : If the Spark operation in the RDD persistence operation less, shuffle operation more, it is recommended to reduce the persistence of the operation of the memory ratio, increase the proportion of shuffle operation memory ratio, to avoid shuffle process too much data when the memory is not enough Use, must be written to the disk, reducing performance. In addition, if you find that the operation due to frequent gc slow operation, which means that the implementation of the user code memory is not enough, then the same proposal to reduce the value of this parameter.
Resource parameters of the tuning, there is no fixed value, the need for students according to their actual situation (including the Spark operation shuffle operation number, RDD persistence operation number and spark web ui show job gc situation), while the reference The principles given in the article as well as the tuning recommendations, reasonably set the above parameters.
Article directory
Spark operation basic operating principle
After applying for the resources required for the execution of the job, the Driver process will begin scheduling and executing the job code we have written. Driver process will be prepared by our Spark job code split into multiple stages, each stage to perform part of the code snippet, and for each stage to create a number of tasks, and then these tasks assigned to the implementation of the various Executor process. Task is the smallest unit of computing, is responsible for the implementation of exactly the same computing logic (that is, we write a code fragment), but each task to deal with the data is different. After all the tasks of a stage are executed, the intermediate result will be written in the local disk file of each node, and then the driver will schedule the next stage to be run. The next stage of the task input data is the result of a stage output on the middle. So the cycle, until we write all the logic of the implementation of all the logic, and calculate all the data, we want the results so far.
Spark is based on shuffle class operator to stage the division. If we execute a shuffle class operator (such as reduceByKey, join, etc.) in our code, we will divide the stage boundary at that operator. Can be roughly understood as, shuffle operator before the implementation of the code will be divided into a stage, shuffle operator implementation and after the code will be divided into the next stage. So a stage just started when it's every task may be from a stage of the task where the node, go through the network transmission to extract all the keys to deal with their own, and then pull all the same key to use We write our own functions to perform aggregate operations (such as the function that the reduceByKey () operator receives). This process is shuffle.
When we execute cache / persist and other persistence operations in the code, the data calculated by each task is saved to the memory of the Executor process or the disk file of the node, depending on the persistence level we choose.
So Executor's memory is divided into three: the first piece is to let the implementation of our own code to use the code, the default is 20% of the total memory of the executive; the second is to let the task through the shuffle process to pull a stage The output of the task, the aggregation and other operations used, the default is also accounted for Executive% of the total memory 20%; third is to use RDD persistence, the default accounted for 60% of executive memory.
Task execution speed is with each Executor process CPU core number is directly related. A CPU core at the same time can only perform a thread. And each Executor process assigned to the multiple tasks, are each way a thread of the way, multi-threaded concurrent operation. If the CPU core number is more adequate, and assigned to the number of tasks more reasonable, then usually speaking, you can more quickly and efficiently perform these task threads.
The above is the basic operating principle of Spark operating instructions, we can combine the map to understand. Understand the basic principles of operation, we are the basic premise of resource parameter tuning.
Resource parameter tuning
After understanding the basics of the Spark job, the resource-related parameters are easy to understand. The so-called Spark resource parameter tuning, in fact, is the Spark operation process of the various use of resources, by adjusting the various parameters to optimize the efficiency of resource use, thereby enhancing the performance of Spark operations. The following parameters are the main resource parameters in Spark, each parameter corresponds to a part of the operating principle of the operation, we also give a tuning of the reference value.Num-executors
Parameter Description: This parameter is used to set the Spark job to use a total of how many Executor process to perform. Driver When applying for resources to the YARN Cluster Manager, the YARN Cluster Manager will, as far as possible, start the corresponding number of Executor processes on the various work nodes of the cluster. This parameter is very important, if not set, then the default will only give you start a small amount of Executor process, this time your Spark operation is very slow.
Parameter tuning recommendations : the operation of each Spark generally set 50 ~ 100 or so Executor process more appropriate, set too little or too many Executor process is not good. Set too little, can not make full use of cluster resources; set too much, most of the queue may not be able to give sufficient resources.
Executor-memory
Parameter Description: This parameter is used to set the memory of each Executor process. Executor memory size, often directly determine the performance of the Spark job, but also with the common JVM OOM exception, there are direct correlation.
Parameter tuning recommendations : each Executor process memory settings 4G ~ 8G more appropriate. But this is only a reference value, the specific settings or according to the different departments of the resource queue to set. You can see their team's resource queue is the largest memory limit, num-executors multiplied by executor-memory, on behalf of your Spark job application to the total amount of memory (that is, all the memory of all Executor process), the amount Is the maximum amount of memory that can not exceed the queue. In addition, if you are sharing this resource queue with someone else on the team, the total amount of memory applied is best not to exceed the 1/3 to 1/2 of the maximum total memory of the resource queue, avoiding your own Spark jobs taking the queue Resources, leading to other students can not run the homework.
Executor-cores
Parameter Description: This parameter is used to set the number of CPU cores for each Executor process. This parameter determines the ability of each Executor process to execute the task thread in parallel. Because each CPU core at the same time can only perform a task thread, so each Executor process CPU core number more, the more able to quickly complete the distribution of all their own task thread.
Parameter tuning recommendations : Executor CPU core number set to 2 to 4 more appropriate. The same according to the different departments of the resource queue to set, you can look at their own resource queue maximum CPU core limit is how much, and then set the number of Executor to determine each Executor process can be assigned to several CPU core. The same proposal, if it is shared with others to the queue, then num-executors * executor-cores do not exceed the total CPU core 1/3 ~ 1/2 or so more appropriate, but also to avoid affecting the operation of other students.
Driver-memory
Parameter Description : This parameter is used to set the memory of the Driver process.
Parameter tuning recommendations : Driver's memory is usually not set, or set about 1G should be enough. The only thing to note is that if you need to use the collect operator to extract all the RDD data to the driver for processing, you must ensure that the driver's memory is large enough, otherwise there will be OOM memory overflow problem.
Spark.default.parallelism
Parameter Description: This parameter is used to set the default number of tasks per stage. This parameter is extremely important, if not set may directly affect your Spark job performance.
Parameter tuning recommendations : Spark job default task number of 500 to 1000 is more appropriate. Many students often make a mistake is not to set this parameter, then this will lead to Spark own HDFS based on the number of blocks to set the number of tasks, the default is a HDFS block corresponding to a task. In general, the number of Spark default settings is too small (for example, dozens of tasks), if the number of tasks less than the case, it will lead you in front of the parameters of the Executor are exhausted. Imagine, no matter how many of your Executor process, memory and CPU how much, but the task is only one or 10, then 90% of the Executor process may not have the task implementation, that is wasted resources! So Spark official website suggested that the principle is to set the parameters for the num-executors * executor-cores 2 to 3 times more appropriate, such as the total number of CPU master CPU total of 300, then set 1000 task is possible, this time Can take full advantage of Spark cluster resources.
Spark.storage.memoryFraction
Parameter Description: This parameter is used to set the RDD persistent data in the Executor memory can account for the proportion of the default is 0.6. In other words, the default Executor 60% of the memory, can be used to save the persistent RDD data. Depending on the different persistence policy you choose, if the memory is not enough, the data may not be persistent, or the data will be written to disk.
Parameter tuning recommendations : If the Spark operation, there are more RDD persistence operation, the value of the parameter can be appropriately improved to ensure that the persistent data can be accommodated in memory. To avoid the memory is not enough to cache all the data, resulting in data can only be written to disk, reducing performance. But if the Spark operation shuffle class operation is more, and the persistence operation is relatively small, then the value of this parameter is appropriate to reduce some of the more appropriate. In addition, if you find that the operation due to frequent gc slow operation (through the spark web ui can be observed that the operating gc time-consuming), means that the implementation of the user code memory is not enough, then the same proposal to reduce the value of this parameter.
Spark.shuffle.memoryFraction
Parameter Description: This parameter is used to set the shuffle process in a task pull to the output of the last stage of the task, the aggregation operation can be used when the proportion of Executor memory, the default is 0.2. In other words, Executor defaults only 20% of the memory used to carry out the operation. Shuffle operation In the polymerization, if you find the use of memory beyond the 20% of the restrictions, then the excess data will be written to the disk file, this time will greatly reduce performance.
Parameter tuning recommendations : If the Spark operation in the RDD persistence operation less, shuffle operation more, it is recommended to reduce the persistence of the operation of the memory ratio, increase the proportion of shuffle operation memory ratio, to avoid shuffle process too much data when the memory is not enough Use, must be written to the disk, reducing performance. In addition, if you find that the operation due to frequent gc slow operation, which means that the implementation of the user code memory is not enough, then the same proposal to reduce the value of this parameter.
Resource parameters of the tuning, there is no fixed value, the need for students according to their actual situation (including the Spark operation shuffle operation number, RDD persistence operation number and spark web ui show job gc situation), while the reference The principles given in the article as well as the tuning recommendations, reasonably set the above parameters.
Resource parameter reference example
The following is a spark-submit command example, we can refer to, and according to their actual situation to adjust:./bin/spark-submit \ --master yarn-cluster \ --num-executors 100 \ --executor-memory 6G \ --executor-cores 4 \ --driver-memory 1G \ --conf spark.default.parallelism=1000 \ --conf spark.storage.memoryFraction=0.5 \ --conf spark.shuffle.memoryFraction=0.3 \ |
This article was reproduced from : http://tech.meituan.com/spark-tuning-basic.html



Commentaires
Enregistrer un commentaire