Spark Performance Optimization: Development Tuning
In the field of large data computing , Spark has become one of the increasingly popular and increasingly popular computing platforms . Spark
's features cover a wide range of computing operations such as offline
batch processing, SQL class processing, streaming / real-time computing,
machine learning, and graph computing, with a wide range of
applications and prospects.
However, it is not that easy to develop high-performance, large data calculations through Spark . If there is no reasonable tuning of Spark operations, Spark operations may be slow to execute, so that Spark can not fully reflect the advantages of a fast data computing engine. Therefore, want to use Spark, it must be a reasonable performance optimization.
Spark's performance tuning is actually composed of many parts, not a few parameters can be adjusted to enhance the performance of immediate performance. We need to according to different business scenarios and data, Spark operations for a comprehensive analysis, and then a number of aspects of regulation and optimization in order to obtain the best performance.
The author based on the previous Spark operation experience and practice accumulation, summed up a set of Spark operations performance optimization program. The whole program is divided into development tuning, resource tuning, data tilt tuning, shuffle tuning several parts. The development of tuning and resource tuning is the basic principle that all Spark operations need to pay attention to and follow, is the basis of high-performance Spark operations; data tilt tuning, the main explanation of a complete set of solutions used to solve the Spark operating data tilt Program; shuffle tuning, for the Spark principle is a deeper level of mastery and research students, mainly on how to Spark operation shuffle operation process and the details of the tuning.
This article serves as a basis for the Spark performance optimization guide, which focuses on development tuning and resource tuning.
We should pay attention to the development process: for the same data, should only create an RDD, can not create multiple RDD to represent the same data.
Some Spark beginners at the beginning of the development of Spark operations, or experienced engineers in the development of RDD lineage extremely lengthy Spark operations, may have forgotten for a certain data has been created before a RDD, which led to With the same data, multiple RDDs were created. This means that our Spark job performs multiple iterations to create multiple RDDs representing the same data, which in turn increases the performance overhead of the job.
A simple example
A simple example
The default principle in Spark for multiple executions of an RDD is this: every time you perform an operator operation on an RDD, it is recalculated from the source, the RDD is calculated, and then executed on the RDD Your operator. The performance of this approach is poor.
So for this situation, our advice is: the use of multiple RDD persistence. At this point Spark will be based on your persistence strategy, the RDD in the data stored in memory or disk. Each time the RDD operator is run, it will extract the persistent RDD data directly from the memory or disk, and then execute the operator without recalculating the RDD from the source and perform the operator operation.
An example of a code that is persisted for multiple use of RDD
For the persist () method, we can choose different persistence levels depending on the business scenario.
Spark's persistence level
How to choose the most appropriate persistence strategy
1, by default, the highest performance of course, is MEMORY_ONLY, but the premise is that your memory must be large enough, you can more than enough to store all the data under the entire RDD. Because of the serialization and deserialization operation, to avoid this part of the performance overhead; on the RDD follow-up operator operations are based on pure memory in the data operation, do not need to read data from the disk file, Performance is also high; and do not need to copy a copy of the data, and remote transmission to other nodes. But it must be noted that in the actual production environment, I am afraid that the scene can be used directly with this strategy is limited, if the RDD data more time (such as billions), directly with this level of persistence, will Causing the OVM memory overflow exception of the JVM.
2, if the use of MEMORY_ONLY level memory overflow occurred, it is recommended to try to use MEMORY_ONLY_SER level. This level will be serialized RDD data and then stored in memory, this time each partition is just a byte array only, greatly reducing the number of objects, and reduce the memory footprint. This level of performance than MEMORY_ONLY out of the cost, mainly serialization and deserialization of the overhead. But the follow-up operator can be based on pure memory operation, so the overall performance is still relatively high. In addition, the problem may occur as above, if the amount of data in the RDD too much, it may lead to OOM memory overflow exception.
3, if the level of pure memory can not be used, it is recommended to use MEMORY_AND_DISK_SER strategy, rather than MEMORY_AND_DISK strategy. Because since this step, it shows that the amount of RDD data is large, the memory can not be completely put down. Serialized data is relatively small, you can save memory and disk space overhead. At the same time the strategy will give priority to try to cache data in memory, memory cache will not write to disk.
4, usually do not recommend the use of DISK_ONLY and suffix of _2 level: because completely based on disk files for data read and write, will lead to a sharp decline in performance, sometimes not as a recalculation of all RDD. With a suffix of _2, all copies of the data must be copied and sent to other nodes. Data replication and network traffic can result in significant performance overhead, which is not recommended unless it is required for high availability.
Shuffle process, the same key on each node will first write to the local disk file, and then the other nodes need to be transmitted through the network to pull the various nodes on the disk file in the same key. And the same key are pulled to the same node for polymerization operations, there may be because a node on the handle too much, resulting in memory is not enough storage, and then overflow to the disk file. So in the shuffle process, there may be a lot of disk file read and write IO operations, and data network transmission operations. Disk IO and network data transmission is also shuffle poor performance of the main reasons.
Therefore, in our development process, we can avoid using as much as possible to reduceByKey, join, distinct, repartition will be shuffle operator, try to use the map class non-shuffle operator. In this case, there is no shuffle operation or only less shuffle operation of the Spark job, can greatly reduce performance overhead.
Broadcast and map for join code examples
The so-called map-side prepolymerization is done by performing an aggregate operation on the same key at each node, similar to the local combiner in MapReduce. After map-side prepolymerization, each node will have only one identical key, because multiple of the same keys are aggregated. Other nodes in the extraction of all nodes on the same key, it will greatly reduce the need to pull the number of data, which also reduces the disk IO and network transmission costs. In general, it is advisable to use the reduceByKey or aggregateByKey operator instead of the groupByKey operator, if possible. Because the reduceByKey and aggregateByKey operators use user-defined functions to prepolymerize the same key locally for each node. And the groupByKey operator is not prepolymerized, and the total amount of data is distributed and transmitted between the nodes of the cluster, and the performance is relatively poor.
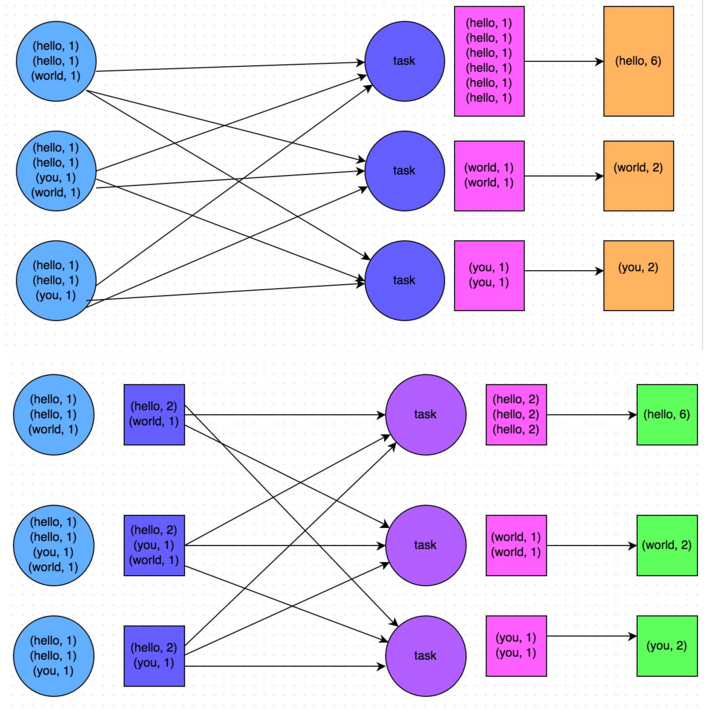
For example, the following figure is a typical example, based on reduceByKey and groupByKey word count. The first picture is the schematic diagram of groupByKey, you can see, without any local aggregation, all data will be transmitted between the cluster nodes; the second map is the schematic diagram of reduceByKey, you can see that each node local Of the same key data, are carried out pre-aggregation, and then transferred to other nodes on the global aggregation.

Use the reduceByKey / aggregateByKey instead of groupByKey
For details, see "Principle 5: Shuffle operation using map-side prepolymerization".
Use mapPartitions instead of plain map
MapPartitions class operator, a function call will deal with a partition of all the data, rather than a function call to deal with a performance will be relatively higher. But sometimes, using mapPartitions will appear OOM (memory overflow) problem. Because a single function call to deal with a partition of all the data, if the memory is not enough, garbage collection can not recover too many objects, it is likely that OOM anomalies. So use this type of operation to be careful!
Use foreachPartitions instead of foreach
The principle is similar to "using mapPartitions instead of map", but also a function call to deal with all the data of a partition, rather than a function call to deal with a data. In practice found that foreachPartitions class of operators, the performance of the upgrade is still very helpful. For example, in the foreach function, the RDD all the data to write MySQL, then if it is a normal foreach operator, it will be a data to write a data, each function call may create a database connection, this time will be frequent To create and destroy the database connection, the performance is very low; but if the foreachPartitions operator to deal with a partition of data, then for each partition, as long as the creation of a database connection can be, and then perform batch insert operation, this time the performance is Relatively high. In practice, found that about 10,000 of the amount of data to write MySQL, performance can be increased by more than 30%.
Use the filter after the coalesce operation
It is common to filter out the RDD in the RDD (for example, more than 30% of the data). It is recommended to use the coalesce operator to manually reduce the number of RDD partitions and compress the data in the RDD into fewer partitions go with. Because the filter, RDD each partition will have a lot of data is filtered out, then if the subsequent follow-up calculation, in fact, each task management partition in the amount of data is not a lot, a little waste of resources, and at this time The more tasks to handle, the slower the speed may be. So use coalesce to reduce the number of partitions, the RDD data compressed to less partition, as long as the use of fewer tasks can handle all the partitions. In some scenarios, for the performance of the upgrade will have some help.
Use repartitionAndSortWithinPartitions instead of repartition and sort operations
RepartitionAndSortWithinPartitions is an operator recommended by Spark, it is recommended that you use the repartitionAndSortWithinPartitions operator if you want to sort after repartition re-partitioning. Because the operator can sort the shuffle operation while re-partitioning it. Shuffle and sort two operations at the same time, than the first shuffle again sort, the performance may be higher.
When an external variable is used in an operator function, by default, Spark copies multiple copies of the variable and transfers it to the task via the network, where each task has a copy of the variable. If the variable itself is relatively large (such as 100M, or even 1G), then a large number of copies of the variable in the network transmission performance overhead, and in the various nodes of the Executor occupied by excessive memory caused by frequent GC, will greatly affect the performance.
Therefore, for the above situation, if the use of external variables is relatively large, it is recommended to use Spark's broadcast function, the variable broadcast. After the broadcast of the variables will ensure that each Executor memory, only a copy of a variable, and Executor in the implementation of the task when the share of the share of the variable copy. In this case, you can greatly reduce the number of variable copies, thereby reducing the performance overhead of network transmission and reduce the memory footprint of Executor memory, reducing the frequency of GC.
Example of code for broadcasting large variables
1, when an external variable is used in the operator function, the variable is serialized for network transmission (see "Principle 7: Broadcasting large variables").
2, the custom type as RDD generic type (such as JavaRDD, Student is a custom type), all custom types of objects, will be serialized. So this case also requires that the custom class must implement the Serializable interface.
3, using a serializable persistence policy (such as MEMORY_ONLY_SER), Spark will serialize each partition in the RDD into a large byte array.
For these three places where serialization occurs, we can optimize the serialization and deserialization performance by using Kryo serialization of the class library. Spark defaults to the Java serialization mechanism, which is the ObjectOutputStream / ObjectInputStream API for serialization and deserialization. But Spark also supports the use of Kryo serialization library, Kryo serialization class library performance than the Java serialization library performance is much higher. Official introduction, Kryo serialization mechanism than Java serialization mechanism, performance is about 10 times higher. Spark did not use Kryo as a serialized library by default because Kryo asked that it would be best to register all the custom types that needed to be serialized, so it was cumbersome for the developer.
The following is an example of using Kryo's code, we just set the serialization class, and then register the serialization type to be serialized (such as the external variable type used in the operator function, as the RDD generic type of custom type, etc.) :
1, the object, each Java object has an object header, reference and other additional information, so compare the use of memory space.
2, the string, each string has a character array inside the length and other additional information.
3, collection types, such as HashMap, LinkedList, etc., because the collection type will usually use some internal class to encapsulate collection elements, such as Map.Entry.
Therefore Spark official suggested that in the Spark encoding implementation, especially for the operator function of the code, try not to use the above three data structures, try to use the string to replace the object, use the original type (such as Int, Long) to replace the string, Use arrays to replace the collection type, which minimizes memory usage, thereby reducing the GC frequency and improving performance.
But in the author's coding practice found that to do this principle is not easy. Because we also take into account the maintainability of the code, if a code, there is no object abstraction, all the way the string stitching, then the follow-up code maintenance and modification is undoubtedly a huge disaster. Similarly, if all operations are based on the array implementation, rather than using HashMap, LinkedList and other collection types, then for our coding and code maintainability, but also a great challenge. Therefore, I suggest that, in the case of possible and appropriate, the use of less memory data structure, but the premise is to ensure the maintainability of the code.
This article was reproduced from : http://tech.meituan.com/spark-tuning-basic.html
However, it is not that easy to develop high-performance, large data calculations through Spark . If there is no reasonable tuning of Spark operations, Spark operations may be slow to execute, so that Spark can not fully reflect the advantages of a fast data computing engine. Therefore, want to use Spark, it must be a reasonable performance optimization.
Spark's performance tuning is actually composed of many parts, not a few parameters can be adjusted to enhance the performance of immediate performance. We need to according to different business scenarios and data, Spark operations for a comprehensive analysis, and then a number of aspects of regulation and optimization in order to obtain the best performance.
The author based on the previous Spark operation experience and practice accumulation, summed up a set of Spark operations performance optimization program. The whole program is divided into development tuning, resource tuning, data tilt tuning, shuffle tuning several parts. The development of tuning and resource tuning is the basic principle that all Spark operations need to pay attention to and follow, is the basis of high-performance Spark operations; data tilt tuning, the main explanation of a complete set of solutions used to solve the Spark operating data tilt Program; shuffle tuning, for the Spark principle is a deeper level of mastery and research students, mainly on how to Spark operation shuffle operation process and the details of the tuning.
This article serves as a basis for the Spark performance optimization guide, which focuses on development tuning and resource tuning.
Article directory
- 1 development tuning
- 1.1 Principle 1: Avoid creating duplicate RDDs
- 1.2 Principle 2: Use the same RDD as much as possible
- 1.3 Principle 3: Use the RDD for multiple use to be persistent
- 1.4 Principle 4: try to avoid using shuffle class operator
- 1.5 Principle 5: Shuffle operation using map-side prepolymerization
- 1.6 Principle 6: Use high-performance operators
- 1.7 Principle 7: Broadcast large variables
- 1.8 Principle 8: Use Kryo to optimize serialization performance
- 1.9 Principle 9: Optimize the data structure
Development tuning
Spark performance optimization of the first step is to develop Spark operations in the process of attention and application of some of the basic principles of performance optimization. Development tuning, is to let everyone understand the following basic principles of the development of Spark, including: RDD lineage design, the rational use of the operator, the optimization of special operations. In the development process, always should pay attention to the above principles, and these principles according to the specific business and practical application scenarios, the flexibility to apply to their own Spark operations.Principle 1: Avoid creating duplicate RDD
In general, when we develop a Spark job, we first create an initial RDD based on a data source (such as a Hive or HDFS file); then perform an operator on the RDD and then get the next RDD; And so on, cycle, until the final results we need to calculate. In this process, multiple RDD will be through different operator operations (such as map, reduce, etc.) string together, the "RDD string", that is, RDD lineage, that is, "RDD blood relationship chain."We should pay attention to the development process: for the same data, should only create an RDD, can not create multiple RDD to represent the same data.
Some Spark beginners at the beginning of the development of Spark operations, or experienced engineers in the development of RDD lineage extremely lengthy Spark operations, may have forgotten for a certain data has been created before a RDD, which led to With the same data, multiple RDDs were created. This means that our Spark job performs multiple iterations to create multiple RDDs representing the same data, which in turn increases the performance overhead of the job.
A simple example
//需要对名为“hello.txt”的HDFS文件进行一次map操作,再进行一次reduce操作。//也就是说,需要对一份数据执行两次算子操作。//错误的做法:对于同一份数据执行多次算子操作时,创建多个RDD。//这里执行了两次textFile方法,针对同一个HDFS文件,创建了两个RDD出来,//然后分别对每个RDD都执行了一个算子操作。//这种情况下,Spark需要从HDFS上两次加载hello.txt文件的内容,并创建两个单独的RDD;//第二次加载HDFS文件以及创建RDD的性能开销,很明显是白白浪费掉的。rdd1.map(...)rdd2.reduce(...)//正确的用法:对于一份数据执行多次算子操作时,只使用一个RDD。//这种写法很明显比上一种写法要好多了,因为我们对于同一份数据只创建了一个RDD,//然后对这一个RDD执行了多次算子操作。//但是要注意到这里为止优化还没有结束,由于rdd1被执行了两次算子操作,第二次执行reduce操作的时候,//还会再次从源头处重新计算一次rdd1的数据,因此还是会有重复计算的性能开销。//要彻底解决这个问题,必须结合“原则三:对多次使用的RDD进行持久化”,//才能保证一个RDD被多次使用时只被计算一次。rdd1.map(...)rdd1.reduce(...) |
Principle 2: Use the same RDD as much as possible
In addition to creating multiple RDDs for a completely identical data during the development process, an RDD is multiplexed as much as possible when performing operator operations on different data. For example, there is an RDD data format is key-value type, the other is a single value type, the two RDD value data is exactly the same. Then we can only use the key-value type of the RDD, because it already contains another data. For data that resembles or contains multiple RDDs, we should try to reuse an RDD so that the number of RDDs can be reduced as much as possible to minimize the number of operator executions.A simple example
// 错误的做法。// 有一个<long , String>格式的RDD,即rdd1。// 接着由于业务需要,对rdd1执行了一个map操作,创建了一个rdd2,//而rdd2中的数据仅仅是rdd1中的value值而已,也就是说,rdd2是rdd1的子集。JavaPairRDD</long><long , String> rdd1 = ...JavaRDD<string> rdd2 = rdd1.map(...)// 分别对rdd1和rdd2执行了不同的算子操作。rdd1.reduceByKey(...)rdd2.map(...)// 正确的做法。// 上面这个case中,其实rdd1和rdd2的区别无非就是数据格式不同而已,//rdd2的数据完全就是rdd1的子集而已,却创建了两个rdd,并对两个rdd都执行了一次算子操作。// 此时会因为对rdd1执行map算子来创建rdd2,而多执行一次算子操作,进而增加性能开销。// 其实在这种情况下完全可以复用同一个RDD。// 我们可以使用rdd1,既做reduceByKey操作,也做map操作。// 在进行第二个map操作时,只使用每个数据的tuple._2,也就是rdd1中的value值,即可。JavaPairRDD<long , String> rdd1 = ...rdd1.reduceByKey(...)rdd1.map(tuple._2...)// 第二种方式相较于第一种方式而言,很明显减少了一次rdd2的计算开销。// 但是到这里为止,优化还没有结束,对rdd1我们还是执行了两次算子操作,rdd1实际上还是会被计算两次。// 因此还需要配合“原则三:对多次使用的RDD进行持久化”进行使用,//才能保证一个RDD被多次使用时只被计算一次。 |
Principle 3: Persistent use of RDD for multiple use
When you have done an operator operation on a RDD several times in the Spark code, congratulations, you have optimized the first step of the Spark job, that is, reuse the RDD as much as possible. At this point on the basis of this, the second step optimization, that is, to ensure that a RDD implementation of a number of operator operations, the RDD itself is only calculated once.The default principle in Spark for multiple executions of an RDD is this: every time you perform an operator operation on an RDD, it is recalculated from the source, the RDD is calculated, and then executed on the RDD Your operator. The performance of this approach is poor.
So for this situation, our advice is: the use of multiple RDD persistence. At this point Spark will be based on your persistence strategy, the RDD in the data stored in memory or disk. Each time the RDD operator is run, it will extract the persistent RDD data directly from the memory or disk, and then execute the operator without recalculating the RDD from the source and perform the operator operation.
An example of a code that is persisted for multiple use of RDD
// 如果要对一个RDD进行持久化,只要对这个RDD调用cache()和persist()即可。// 正确的做法。// cache()方法表示:使用非序列化的方式将RDD中的数据全部尝试持久化到内存中。// 此时再对rdd1执行两次算子操作时,只有在第一次执行map算子时,才会将这个rdd1从源头处计算一次。// 第二次执行reduce算子时,就会直接从内存中提取数据进行计算,不会重复计算一个rdd。rdd1.map(...)rdd1.reduce(...)// persist()方法表示:手动选择持久化级别,并使用指定的方式进行持久化。// 比如说,StorageLevel.MEMORY_AND_DISK_SER表示,内存充足时优先持久化到内存中,//内存不充足时持久化到磁盘文件中。// 而且其中的_SER后缀表示,使用序列化的方式来保存RDD数据,此时RDD中的每个partition//都会序列化成一个大的字节数组,然后再持久化到内存或磁盘中。// 序列化的方式可以减少持久化的数据对内存/磁盘的占用量,进而避免内存被持久化数据占用过多,//从而发生频繁GC。.persist(StorageLevel.MEMORY_AND_DISK_SER)rdd1.map(...)rdd1.reduce(...) |
Spark's persistence level
| Persistence level | Meaning interpretation |
|---|---|
| MEMORY_ONLY | Use unadjusted Java object format to save the data in memory. If the memory is not enough to store all the data, the data may not be persistent. Then the next time the RDD implementation of the operator operation, those who have not been persistent data, need to recalculate from the source again. This is the default persistence strategy that uses the cache () method when actually using this persistence policy. |
| MEMORY_AND_DISK | Use the unadjusted Java object format to give priority to saving the data in memory. If the memory is not enough to store all the data, the data will be written to the disk file, the next time the RDD implementation of the operator, the data persisted in the disk file will be read out to use. |
| MEMORY_ONLY_SER | Basic meaning with MEMORY_ONLY. The only difference is that the data in the RDD will be serialized, each partition of the RDD will be serialized into a byte array. This way more savings in memory, which can prevent persistent data from consuming too much memory to cause frequent GC. |
| MEMORY_AND_DISK_SER | The basic meaning is the same as MEMORY_AND_DISK. The only difference is that the data in the RDD will be serialized, each partition of the RDD will be serialized into a byte array. This way more savings in memory, which can prevent persistent data from consuming too much memory to cause frequent GC. |
| DISK_ONLY | Use the unformulated Java object format to write all the data to a disk file. |
| MEMORY_ONLY_2, MEMORY_AND_DISK_2, etc. | For any of the persistence policies described above, if the suffix _2 is added, it means that each persistent data is copied and a copy is saved to the other node. This copy-based persistence mechanism is primarily used for fault tolerance. If a node hangs, the node's memory or persistent data in the disk is lost, then a copy of the data on the other node can also be used for subsequent RDD calculations. If there is no copy of the words, it can only be the data from the source to recalculate it again. |
1, by default, the highest performance of course, is MEMORY_ONLY, but the premise is that your memory must be large enough, you can more than enough to store all the data under the entire RDD. Because of the serialization and deserialization operation, to avoid this part of the performance overhead; on the RDD follow-up operator operations are based on pure memory in the data operation, do not need to read data from the disk file, Performance is also high; and do not need to copy a copy of the data, and remote transmission to other nodes. But it must be noted that in the actual production environment, I am afraid that the scene can be used directly with this strategy is limited, if the RDD data more time (such as billions), directly with this level of persistence, will Causing the OVM memory overflow exception of the JVM.
2, if the use of MEMORY_ONLY level memory overflow occurred, it is recommended to try to use MEMORY_ONLY_SER level. This level will be serialized RDD data and then stored in memory, this time each partition is just a byte array only, greatly reducing the number of objects, and reduce the memory footprint. This level of performance than MEMORY_ONLY out of the cost, mainly serialization and deserialization of the overhead. But the follow-up operator can be based on pure memory operation, so the overall performance is still relatively high. In addition, the problem may occur as above, if the amount of data in the RDD too much, it may lead to OOM memory overflow exception.
3, if the level of pure memory can not be used, it is recommended to use MEMORY_AND_DISK_SER strategy, rather than MEMORY_AND_DISK strategy. Because since this step, it shows that the amount of RDD data is large, the memory can not be completely put down. Serialized data is relatively small, you can save memory and disk space overhead. At the same time the strategy will give priority to try to cache data in memory, memory cache will not write to disk.
4, usually do not recommend the use of DISK_ONLY and suffix of _2 level: because completely based on disk files for data read and write, will lead to a sharp decline in performance, sometimes not as a recalculation of all RDD. With a suffix of _2, all copies of the data must be copied and sent to other nodes. Data replication and network traffic can result in significant performance overhead, which is not recommended unless it is required for high availability.
Principle 4: try to avoid using the shuffle class operator
If possible, try to avoid using shuffle class operators. Because the Spark job is running, the most costly performance is the shuffle process. Shuffle process, in simple terms, is distributed in the cluster of multiple nodes on the same key, pulled to the same node, the polymerization or join and other operations. Such as reduceByKey, join and other operators, will trigger shuffle operation.Shuffle process, the same key on each node will first write to the local disk file, and then the other nodes need to be transmitted through the network to pull the various nodes on the disk file in the same key. And the same key are pulled to the same node for polymerization operations, there may be because a node on the handle too much, resulting in memory is not enough storage, and then overflow to the disk file. So in the shuffle process, there may be a lot of disk file read and write IO operations, and data network transmission operations. Disk IO and network data transmission is also shuffle poor performance of the main reasons.
Therefore, in our development process, we can avoid using as much as possible to reduceByKey, join, distinct, repartition will be shuffle operator, try to use the map class non-shuffle operator. In this case, there is no shuffle operation or only less shuffle operation of the Spark job, can greatly reduce performance overhead.
Broadcast and map for join code examples
// 传统的join操作会导致shuffle操作。// 因为两个RDD中,相同的key都需要通过网络拉取到一个节点上,由一个task进行join操作。val rdd3 = rdd1.join(rdd2)// Broadcast+map的join操作,不会导致shuffle操作。// 使用Broadcast将一个数据量较小的RDD作为广播变量。val rdd2Data = rdd2.collect()val rdd2DataBroadcast = sc.broadcast(rdd2Data)// 在rdd1.map算子中,可以从rdd2DataBroadcast中,获取rdd2的所有数据。// 然后进行遍历,如果发现rdd2中某条数据的key与rdd1的当前数据的key是相同的,//那么就判定可以进行join。// 此时就可以根据自己需要的方式,将rdd1当前数据与rdd2中可以连接的数据,//拼接在一起(String或Tuple)。val rdd3 = rdd1.map(rdd2DataBroadcast...)// 注意,以上操作,建议仅仅在rdd2的数据量比较少(比如几百M,或者一两G)的情况下使用。// 因为每个Executor的内存中,都会驻留一份rdd2的全量数据。 |
Principle 5: Use the shuffle operation of the map-side prepolymerization
If you need to use the shuffle operation because of business needs, you can not use the map class operator to replace, then try to use the map-side prepolymerization operator.The so-called map-side prepolymerization is done by performing an aggregate operation on the same key at each node, similar to the local combiner in MapReduce. After map-side prepolymerization, each node will have only one identical key, because multiple of the same keys are aggregated. Other nodes in the extraction of all nodes on the same key, it will greatly reduce the need to pull the number of data, which also reduces the disk IO and network transmission costs. In general, it is advisable to use the reduceByKey or aggregateByKey operator instead of the groupByKey operator, if possible. Because the reduceByKey and aggregateByKey operators use user-defined functions to prepolymerize the same key locally for each node. And the groupByKey operator is not prepolymerized, and the total amount of data is distributed and transmitted between the nodes of the cluster, and the performance is relatively poor.
For example, the following figure is a typical example, based on reduceByKey and groupByKey word count. The first picture is the schematic diagram of groupByKey, you can see, without any local aggregation, all data will be transmitted between the cluster nodes; the second map is the schematic diagram of reduceByKey, you can see that each node local Of the same key data, are carried out pre-aggregation, and then transferred to other nodes on the global aggregation.
Principle 6: Use high-performance operators
In addition to shuffle related operators have optimization principles, the other operators also have a corresponding optimization principle.Use the reduceByKey / aggregateByKey instead of groupByKey
For details, see "Principle 5: Shuffle operation using map-side prepolymerization".
Use mapPartitions instead of plain map
MapPartitions class operator, a function call will deal with a partition of all the data, rather than a function call to deal with a performance will be relatively higher. But sometimes, using mapPartitions will appear OOM (memory overflow) problem. Because a single function call to deal with a partition of all the data, if the memory is not enough, garbage collection can not recover too many objects, it is likely that OOM anomalies. So use this type of operation to be careful!
Use foreachPartitions instead of foreach
The principle is similar to "using mapPartitions instead of map", but also a function call to deal with all the data of a partition, rather than a function call to deal with a data. In practice found that foreachPartitions class of operators, the performance of the upgrade is still very helpful. For example, in the foreach function, the RDD all the data to write MySQL, then if it is a normal foreach operator, it will be a data to write a data, each function call may create a database connection, this time will be frequent To create and destroy the database connection, the performance is very low; but if the foreachPartitions operator to deal with a partition of data, then for each partition, as long as the creation of a database connection can be, and then perform batch insert operation, this time the performance is Relatively high. In practice, found that about 10,000 of the amount of data to write MySQL, performance can be increased by more than 30%.
Use the filter after the coalesce operation
It is common to filter out the RDD in the RDD (for example, more than 30% of the data). It is recommended to use the coalesce operator to manually reduce the number of RDD partitions and compress the data in the RDD into fewer partitions go with. Because the filter, RDD each partition will have a lot of data is filtered out, then if the subsequent follow-up calculation, in fact, each task management partition in the amount of data is not a lot, a little waste of resources, and at this time The more tasks to handle, the slower the speed may be. So use coalesce to reduce the number of partitions, the RDD data compressed to less partition, as long as the use of fewer tasks can handle all the partitions. In some scenarios, for the performance of the upgrade will have some help.
Use repartitionAndSortWithinPartitions instead of repartition and sort operations
RepartitionAndSortWithinPartitions is an operator recommended by Spark, it is recommended that you use the repartitionAndSortWithinPartitions operator if you want to sort after repartition re-partitioning. Because the operator can sort the shuffle operation while re-partitioning it. Shuffle and sort two operations at the same time, than the first shuffle again sort, the performance may be higher.
Principle 7: Broadcast large variables
Sometimes in the development process, you will encounter the need to use external variables in the operator function of the scene (especially large variables, such as 100M or more large collection), then this time should use the Spark broadcast (Broadcast) function to improve performance TheWhen an external variable is used in an operator function, by default, Spark copies multiple copies of the variable and transfers it to the task via the network, where each task has a copy of the variable. If the variable itself is relatively large (such as 100M, or even 1G), then a large number of copies of the variable in the network transmission performance overhead, and in the various nodes of the Executor occupied by excessive memory caused by frequent GC, will greatly affect the performance.
Therefore, for the above situation, if the use of external variables is relatively large, it is recommended to use Spark's broadcast function, the variable broadcast. After the broadcast of the variables will ensure that each Executor memory, only a copy of a variable, and Executor in the implementation of the task when the share of the share of the variable copy. In this case, you can greatly reduce the number of variable copies, thereby reducing the performance overhead of network transmission and reduce the memory footprint of Executor memory, reducing the frequency of GC.
Example of code for broadcasting large variables
// 以下代码在算子函数中,使用了外部的变量。// 此时没有做任何特殊操作,每个task都会有一份list1的副本。val list1 = ...rdd1.map(list1...)// 以下代码将list1封装成了Broadcast类型的广播变量。// 在算子函数中,使用广播变量时,首先会判断当前task所在Executor内存中,是否有变量副本。// 如果有则直接使用;如果没有则从Driver或者其他Executor节点上远程拉取一份放到本地Executor内存中。// 每个Executor内存中,就只会驻留一份广播变量副本。val list1 = ...val list1Broadcast = sc.broadcast(list1)rdd1.map(list1Broadcast...) |
Principle 8: Use Kryo to optimize serialization performance
In Spark, there are three main places that involve serialization:1, when an external variable is used in the operator function, the variable is serialized for network transmission (see "Principle 7: Broadcasting large variables").
2, the custom type as RDD generic type (such as JavaRDD, Student is a custom type), all custom types of objects, will be serialized. So this case also requires that the custom class must implement the Serializable interface.
3, using a serializable persistence policy (such as MEMORY_ONLY_SER), Spark will serialize each partition in the RDD into a large byte array.
For these three places where serialization occurs, we can optimize the serialization and deserialization performance by using Kryo serialization of the class library. Spark defaults to the Java serialization mechanism, which is the ObjectOutputStream / ObjectInputStream API for serialization and deserialization. But Spark also supports the use of Kryo serialization library, Kryo serialization class library performance than the Java serialization library performance is much higher. Official introduction, Kryo serialization mechanism than Java serialization mechanism, performance is about 10 times higher. Spark did not use Kryo as a serialized library by default because Kryo asked that it would be best to register all the custom types that needed to be serialized, so it was cumbersome for the developer.
The following is an example of using Kryo's code, we just set the serialization class, and then register the serialization type to be serialized (such as the external variable type used in the operator function, as the RDD generic type of custom type, etc.) :
// 创建SparkConf对象。val conf = new SparkConf().setMaster(...).setAppName(...)// 设置序列化器为KryoSerializer。conf.set("spark.serializer", "org.apache.spark.serializer.KryoSerializer")// 注册要序列化的自定义类型。conf.registerKryoClasses(Array(classOf[MyClass1], classOf[MyClass2])) |
Principle 9: Optimize the data structure
Java, there are three types of more memory:1, the object, each Java object has an object header, reference and other additional information, so compare the use of memory space.
2, the string, each string has a character array inside the length and other additional information.
3, collection types, such as HashMap, LinkedList, etc., because the collection type will usually use some internal class to encapsulate collection elements, such as Map.Entry.
Therefore Spark official suggested that in the Spark encoding implementation, especially for the operator function of the code, try not to use the above three data structures, try to use the string to replace the object, use the original type (such as Int, Long) to replace the string, Use arrays to replace the collection type, which minimizes memory usage, thereby reducing the GC frequency and improving performance.
But in the author's coding practice found that to do this principle is not easy. Because we also take into account the maintainability of the code, if a code, there is no object abstraction, all the way the string stitching, then the follow-up code maintenance and modification is undoubtedly a huge disaster. Similarly, if all operations are based on the array implementation, rather than using HashMap, LinkedList and other collection types, then for our coding and code maintainability, but also a great challenge. Therefore, I suggest that, in the case of possible and appropriate, the use of less memory data structure, but the premise is to ensure the maintainability of the code.
This article was reproduced from : http://tech.meituan.com/spark-tuning-basic.html



This post ok to understand spark, but middle china characters available. its little difficult to understand .. thanks to share referance as well. Ill follow
RépondreSupprimerVenu spark training in Hyderabad
bigdata training in Hyderabad