Spark Performance Tuning: Data Tilt Tuning
Article directory
2, the original can be the normal implementation of the Spark operation, one day suddenly reported OOM (memory overflow) exception, observe the abnormal stack, we write the business code caused. This is rare.
So when the data is tilted, the Spark job looks very slow, and may even cause a memory overflow due to a large amount of data handled by a task.
The following figure is a very clear example: hello the key, in the three nodes corresponding to a total of seven data, these data will be drawn to the same task for processing; and the world and you these two keys were corresponding 1 data, so the other two tasks as long as the processing of a single data can be. At this point the first task of the run time may be two other tasks 7 times, and the entire stage of the running speed is also determined by the slowest run of the task.

If you are using the yarn-client mode to submit, then the local can directly see the log, you can find the current log to run the first few stages; if it is submitted using the yarn-cluster mode, you can use the Spark Web UI to view the current Run to the first few stages. In addition, both the use of yarn-client mode or the yarn-cluster mode, we can in the Spark Web UI in-depth look at the current stage of the task assigned the amount of each task to further determine whether the data distribution is not task data lead to data tilt.
For example, the figure below, the penultimate column shows the run time of each task. Obviously you can see that some tasks run very fast, only need a few seconds to run; and some tasks run particularly slow, take a few minutes to run End, this time from the run point of time has been able to determine the occurrence of The data is tilted. In addition, the penultimate column shows the amount of data handled by each task, obviously you can see that the run time is particularly short task only need to deal with hundreds of KB of data can be, and run time particularly long task need to handle thousands of KB Of the data, the amount of data processed by the difference of 10 times. At this point more able to determine the occurrence of data tilt.
Know that the data tilt occurs after which stage, then we need to divide the principle according to the stage, calculate the tilt of the stage corresponding to which part of the code, this part of the code will certainly have a shuffle class operator. Accurate calculation of the corresponding relationship between the stage and the code, the need for Spark source code in-depth understanding, where we can introduce a relatively simple and practical calculation method: as long as the Spark code to see a shuffle class operator or Spark SQL SQL Statement appears will lead to shuffle statements (such as group by statement), then you can determine, to that place for the boundaries of the two before and after the stage.
Here we have to Spark the most basic entry procedures - word count to example, how to use the most simple way to roughly calculate a stage corresponding to the code. The following example, in the entire code, only one reduceByKey will happen shuffle operator, so you can think that the operator for the boundaries, will be divided before and after the two stages.
1, stage0, mainly from the implementation of the textFile to map operation, and the implementation of shuffle write operation. Shuffle write operation, we can simply understand the data for pairs RDD in the partition operation, each task processing data, the same key will be written into the same disk file.
2, stage1, mainly from the implementation of the operation from the reduceByKey to collect, stage1 of the various tasks began to run, it will first perform shuffle read operation. The implementation of shuffle read operation of the task, from stage0 each task node to pull their own processing of those keys, and then the same key for a global aggregation or join operations, here is the key value of the cumulative value. Stage1 After executing the implementation of the reduceByKey operator, the final wordCounts RDD is calculated and the collect operator is executed. All the data is drawn to the driver for us to traverse and print the output.
But we should pay attention to is that you can not simply rely on accidental memory overflow to determine the data tilt occurred. Because of their own code to write the bug, as well as accidental data anomalies, may also lead to memory overflow. So in accordance with the above method, through the Spark Web UI to see the report of the stage of the task of the task time and the amount of data allocated to determine whether it is due to data tilt caused the memory overflow.
At this point according to your operation of the different circumstances, there can be a variety of ways to see the key distribution:
1, if it is Spark SQL group by, join statement caused by the data tilt, then check the SQL used in the table key distribution.
2, if the Spark RDD implementation of the shuffle operator caused by the data tilt, then you can add in the Spark operation to see the key distribution of the code, such as RDD.countByKey (). And then out of the statistics of the number of the emergence of the key, collect / take to the client to print, you can see the distribution of key.
For example, for the word count program described above, if it is determined that the stageB's reduceByKey operator causes data skew, then the key distribution in the RDD for the reduceByKey operation should be looked at. In this example, RDD. In the following example, we can first sample 10% of the sample data, and then use the countByKey operator to count the number of occurrences of each key, and finally in the client traversal and print the sample data in the number of occurrences of each key.
Scenario Implementation: At this point you can assess whether you can use Hive for data preprocessing (that is, the Hive ETL pre-aggregates the data according to the key, or joins with other tables in advance), and then the data for the Spark job The source is not the original Hive table, but the pretreatment of the Hive table. At this point because the data has been pre-polymerization or join operation, then the Spark operation also do not need to use the original shuffle class operator to perform such operations.
Program implementation principle: This solution from the root causes to solve the data tilt, because the Spark in the implementation of the shuffle class operator, then there is certainly no data tilt problem. But here also to remind you that this approach is a temporary solution. Because after all, the data itself there is uneven distribution of the problem, so Hive ETL group by or join shuffle operation, or there will be data tilt, resulting in Hive ETL speed is very slow. We just put the data tilt occurred in advance to the Hive ETL, Spark program to avoid data tilt.
Program advantages: to achieve simple and convenient, the effect is also very good, completely avoid the data tilt, Spark job performance will be greatly improved.
Program shortcomings: temporary solution, Hive ETL or data will occur in the tilt.
Program practice experience: In some Java systems and Spark combination of the use of the project, there will be frequent calls to Spark Queask scene, and the Spark operation performance requirements are very high, it is more suitable for the use of this program. The data is tilted forward to the upstream Hive ETL, only once a day, only then that is relatively slow, and then every time Java calls Spark operations, the implementation speed will be very fast, can provide a better user experience.
Project practice experience: This program is used in the interactive user behavior analysis system of the US group. The system mainly allows the user to submit the data analysis and statistics task through the Java Web system. The back-end is submitted to the Spark operation by Java for data analysis. The Spark operation speed must be fast, as far as possible within 10 minutes, otherwise the speed is too slow, the user experience will be poor. So we will be some Spark operations shuffle operation ahead of the Hive ETL, so that Spark directly using the pretreatment of the Hive intermediate table, as much as possible to reduce Spark's shuffle operation, greatly enhance the performance, part of the performance of the upgrade 6 Times more than.
Solution to achieve the idea: If we judge that a small number of data in particular the number of key, the implementation of the operation and the results are not particularly important, then simply filter out a few key directly. For example, in the Spark SQL can use the where clause to filter out the key or in the Spark Core RDD filter operator to filter out the key. If you need to dynamically determine which key data and then filter, you can use the sample operator to sample the RDD, and then calculate the number of each key, the maximum amount of data to filter out the key can.
Program to achieve the principle: the data will lead to tilt the key to filter out, the key will not participate in the calculation, it is impossible to produce data tilt.
Program advantages: to achieve a simple, and the effect is also very good, you can completely avoid the data tilt.
Program shortcomings: the application of the scene is not much, in most cases, leading to the tilt of the key or a lot, not only a few.
Program practice experience: In the project we have also adopted this program to solve the data tilt. Once found a day Spark operation in the run when the sudden OOM, and found after tracing, is a key in the Hive table in the day of data anomalies, resulting in data surge. So to take each time before the implementation of sampling, calculate the maximum amount of data in the sample after a few key, directly in the process of those keys to filter out.
Solution implementation : In the implementation of shuffle operator RDD, shuffle operator to pass a parameter, such as reduceByKey (1000), the parameters set the shuffle operator shuffle read task implementation of the number. For Spark SQL in the shuffle class statement, such as group by, join, need to set a parameter, that is, spark.sql.shuffle.partitions, this parameter represents the shuffle read task parallelism, the value of the default is 200, for many scenes It is a bit too small.
Program to achieve the principle: increase the number of shuffle read task, you can make the original assigned to a task multiple assigned to multiple tasks, so that each task to deal with less than the original data. For example, if there are five key, each key corresponds to 10 data, these five keys are assigned to a task, then the task will deal with 50 data. And increase the shuffle read task later, each task is assigned to a key, that is, each task to deal with 10 data, then the natural implementation of each task will be shorter. The specific principles are shown below.
Program advantages: to achieve relatively simple, can effectively alleviate and mitigate the impact of data tilt.
Program shortcomings: just to ease the data tilt it, did not completely eradicate the problem, according to practical experience, its effect is limited.
Program practice experience: the program is usually unable to completely solve the data tilt, because if there are some extreme cases, such as a key corresponding to the amount of data there are 100 million, then no matter how much your task increased to the number of the corresponding 1 million data key Certainly will be assigned to a task to deal with, so destined to still occur data tilt. So this program can only be said to find the data in the tilt when trying to use the first means, try to use the simple way to ease the data tilt, or is combined with other programs used.
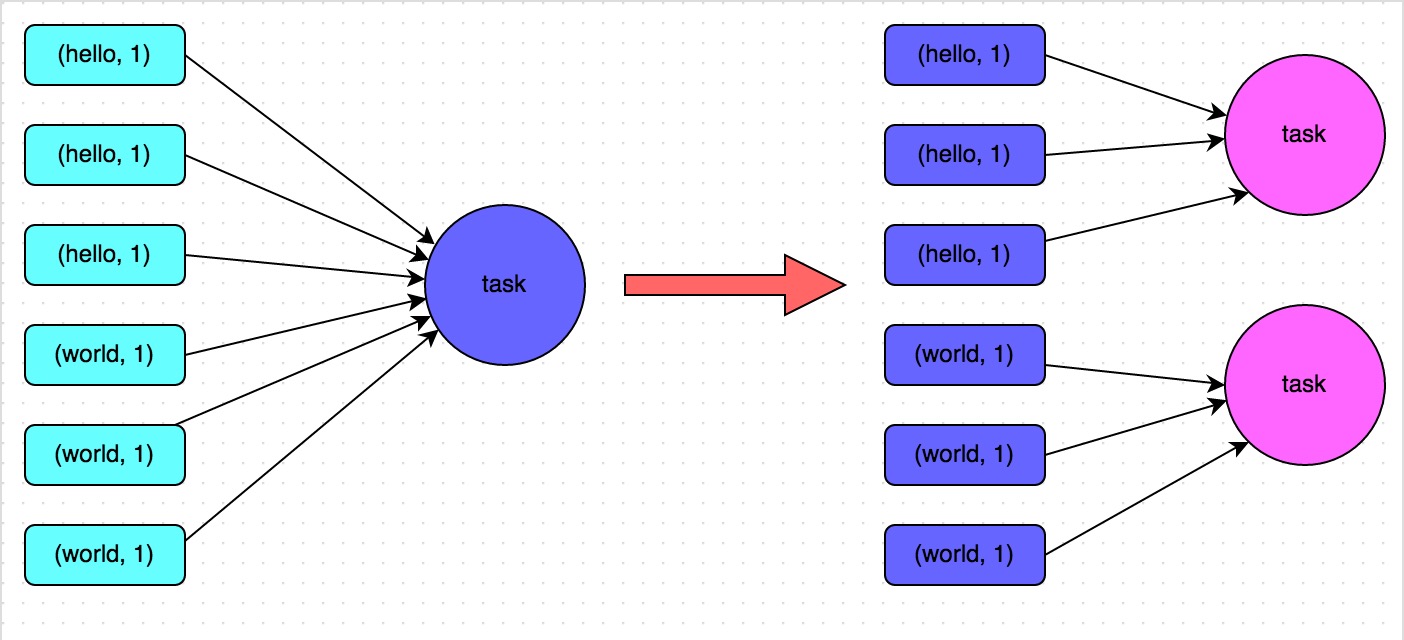
Program implementation ideas: the core of this program is the idea of two-stage aggregation. The first time is a local aggregation, give each key are marked with a random number, such as 10 within the random number, then the same as the original key becomes different, such as (hello, 1) (hello, 1) (1_hello, 1) (1_hello, 1) (2_hello, 1) (2_hello, 1) (hello, 1) (hello, 1) (1_hello, 2) (2_hello, 2), then the local aggregation result will be converted to (1_hello, 2) (2_hello, 2), then the local aggregation will be performed by performing the aggregation operation such as reduceByKey. And then the prefix of each key to be removed, it will become (hello, 2) (hello, 2), again global aggregation operation, you can get the final result, such as (hello, 4).
Program to achieve the principle: the original key through the additional random prefix way, into a number of different keys, you can let the original data processing a decentralized to a number of tasks up to do the local aggregation, and then solve a single task processing data Excessive problems. Then remove the random prefix, again global aggregation, you can get the final result. Specific principles see below.
Advantages of the program: the shuffle operation for the aggregation caused by the data tilt, the effect is very good. Usually can solve the data tilt, or at least a significant ease of data tilt, Spark job performance can be improved several times.
Program Disadvantages: only apply to the shuffle operation of the polymerization class, the scope of application is relatively narrow. If the join class shuffle operation, have to use other solutions.
Program implementation ideas: do not use the join operator to connect operations, and the use of Broadcast variables and map class operator to achieve join operation, and thus completely avoid the shuffle class operation, completely avoid the occurrence of data tilt and appear. The data in the smaller RDD is directly passed through the collect operator to the MCU's memory, and then a Broadcast variable is created; then the map class operator is executed on the other RDD. Within the operator function, from the Broadcast variable Get the full amount of RDD data, and the current RDD for each data according to the connection key to match, if the connection key is the same, then the two RDD data you need to connect the way.
Program to achieve the principle: the ordinary join will take the shuffle process, and once shuffle, it is equivalent to the same key data will be pulled to a shuffle read task and then join, this time is reduce join. But if a RDD is relatively small, you can use the broadcast small RDD full data + map operator to achieve the same effect with the join, that is, map join, this time will not happen shuffle operation, it will not occur data tilt The The specific principles are shown below.
Program advantages: the join operation caused by the data tilt, the effect is very good, because there will not be shuffle, it will not happen data tilt.
Program Disadvantages: Applicable to the scene less, because this program only applies to a large table and a small table of the situation. After all, we need to broadcast a small table, this time will be more consumption of memory resources, drivers and each Executor memory will run a small RDD full amount of data. If we broadcast out of the RDD data is relatively large, such as 10G or more, then it may happen memory overflow. So it is not suitable for both large tables.
Program to achieve ideas:
1, on the inclusion of a small number of data over the key of the RDD, through the sample operator to sample a sample, and then statistics about the number of each key, calculated the largest amount of data which is the number of key.
2, and then these key corresponding to the data from the original RDD split out to form a separate RDD, and each key are marked with n within the random number as a prefix, and will not lead to the tilt of most of the key Form another RDD.
3, then the need to join another RDD, but also filter out a few tilt key corresponding to the data and the formation of a separate RDD, each data expansion into n data, which n data in order to attach a 0 ~ The prefix of n does not cause the tilt of most of the keys to also form another RDD.
4, and then add a random prefix of the independent RDD and another expansion of n times the independent RDD join, this time you can be the same key to break up into n, scattered to multiple tasks to join.
5, while the other two ordinary RDD can join as usual.
6, and finally the results of the two join using union operator can be combined, that is, the final join results.
Program implementation principle : For the data caused by the tilt of the join, if only a few key lead to the tilt, you can split a few key into an independent RDD, and add a random prefix to break up to n to join, this time A key corresponding to the data will not focus on a few tasks, but distributed to multiple tasks for the join. Specific principles see below.
Advantages of the program: the data caused by the tilt of the join, if only a few key led to the tilt, the use of the way you can use the most effective way to break up the key to join. And only need for a small number of tilt key corresponding to the data expansion n times, do not need to expand the full amount of data. To avoid taking up too much memory.
Solution Disadvantages: If the resulting key is particularly tilted, such as thousands of keys are leading to data tilt, then this approach is not suitable.
Program to achieve ideas:
1, the implementation of the program ideas and "solution six" similar to the first look at the RDD / Hive table data distribution, find that data caused by the tilt of the RDD / Hive table, such as multiple keys are corresponding to more than 1 million Article data.
2, and then the RDD of each data are marked with a random prefix within n.
3, while another normal RDD expansion, each data are expanded into n data, the expansion of each data are followed by a 0 ~ n prefix.
4, the last two after the RDD can join.
Program to achieve the principle: the original key through the additional random prefix into a different key, and then these can be processed after the "different key" to a number of tasks to deal with, rather than a task to deal with a large number of the same Key. The difference between the scheme and "solution six" is that the last solution is to treat the data corresponding to a small number of slanted keys as much as possible. Since the process needs to expand RDD, the latter scheme expands RDD to memory Of the occupation is not large; and this kind of program is for a large number of tilt key situation, can not be part of the key split out separately for processing, so only the entire RDD data expansion, the memory resource requirements are high.
Program advantages: the join type of data tilt can be basically the basic treatment, and the effect is relatively significant, performance improvement effect is very good.
Program Disadvantages: The program is more to ease the data tilt, rather than completely avoid data tilt.And the need for expansion of the entire RDD, memory resource demanding.
Program experience: have developed a data needs, they found a lead to join the data skew. Prior to optimization, the job execution time is about 60 minutes; then optimized using this program, the execution time is shortened to about 10 minutes, 6-fold increase in performance.
- 1 Preface
- 2 data tilt tuning
- 2.1 Tuning Overview
- 2.2 The phenomenon of data tilt occurs
- 2.3 Principle of data tilt
- 2.4 How to locate the code that causes the data to tilt
- 2.5 View the data distribution of the key that caused the data to be tilted
- 2.6 data tilt solution
- 2.6.1 Solution 1: Prepare data using Hive ETL
- 2.6.2 Solution 2: Filtering a few causes a tilted key
- 2.6.3 Solution 3: Improve the parallelism of the shuffle operation
- 2.6.4 Solution 4: Two-stage aggregation (local aggregation + global aggregation)
- 2.6.5 Solution 5: reduce join into map join
- 2.6.6 Solution 6: Sampling the tilt key and splitting the join operation
- 2.6.7 Solution 7: Join with random prefix and expansion RDD
- 2.6.8 Solution 8: A combination of multiple scenarios
Preface
Following the "Spark Performance Tuning: Development Tuning" and "Spark Performance Tuning: Resource Tuning", we discuss the development tuning and resource tuning that every Spark developer must know as a " Spark Performance Tuning Guide" The advanced articles will delve into the data tilt tuning and shuffle tuning to address more difficult performance issues.Data tilt tuning
Summary of tuning
Sometimes, we may encounter one of the toughest problems in the big data calculation - the data is tilted, and the performance of the Spark job is much worse than expected. Data tilt tuning, is to use a variety of technical solutions to solve different types of data tilt problems to ensure the performance of Spark operations.The phenomenon of data tilt occurs
1, the vast majority of the implementation of the task are very fast, but the implementation of individual task very slow. For example, a total of 1000 task, 997 tasks are completed within 1 minute, but the remaining two or three tasks have to one or two hours. This is very common.2, the original can be the normal implementation of the Spark operation, one day suddenly reported OOM (memory overflow) exception, observe the abnormal stack, we write the business code caused. This is rare.
The principle of data tilt occurs
The principle of data tilt is very simple: shuffle in the time, must be the same node on each node to pull a node on a task to deal with, such as according to the key aggregation or join and other operations. At this time if a key corresponding to the amount of data is particularly large, it will occur data tilt. For example, most of the key corresponds to 10 data, but the individual key corresponds to 1 million of data, then most of the task may only be assigned to 10 data, and then run for 1 second; but the individual task may be assigned to 1 million Data to run for an hour or two. Therefore, the progress of the entire Spark operation is determined by the longest running time.So when the data is tilted, the Spark job looks very slow, and may even cause a memory overflow due to a large amount of data handled by a task.
The following figure is a very clear example: hello the key, in the three nodes corresponding to a total of seven data, these data will be drawn to the same task for processing; and the world and you these two keys were corresponding 1 data, so the other two tasks as long as the processing of a single data can be. At this point the first task of the run time may be two other tasks 7 times, and the entire stage of the running speed is also determined by the slowest run of the task.

How to locate the code that causes the data to tilt
Data skew only occurs during shuffle. Here are some of the commonly used and may trigger shuffle operation of the operator: distinct, groupByKey, reduceByKey, aggregateByKey, join, cogroup, repartition and so on. When the data is tilted, it may be that one of these operators is used in your code.A task is particularly slow
The first thing to look at is that data skips occur in the first few stages.If you are using the yarn-client mode to submit, then the local can directly see the log, you can find the current log to run the first few stages; if it is submitted using the yarn-cluster mode, you can use the Spark Web UI to view the current Run to the first few stages. In addition, both the use of yarn-client mode or the yarn-cluster mode, we can in the Spark Web UI in-depth look at the current stage of the task assigned the amount of each task to further determine whether the data distribution is not task data lead to data tilt.
For example, the figure below, the penultimate column shows the run time of each task. Obviously you can see that some tasks run very fast, only need a few seconds to run; and some tasks run particularly slow, take a few minutes to run End, this time from the run point of time has been able to determine the occurrence of The data is tilted. In addition, the penultimate column shows the amount of data handled by each task, obviously you can see that the run time is particularly short task only need to deal with hundreds of KB of data can be, and run time particularly long task need to handle thousands of KB Of the data, the amount of data processed by the difference of 10 times. At this point more able to determine the occurrence of data tilt.

Know that the data tilt occurs after which stage, then we need to divide the principle according to the stage, calculate the tilt of the stage corresponding to which part of the code, this part of the code will certainly have a shuffle class operator. Accurate calculation of the corresponding relationship between the stage and the code, the need for Spark source code in-depth understanding, where we can introduce a relatively simple and practical calculation method: as long as the Spark code to see a shuffle class operator or Spark SQL SQL Statement appears will lead to shuffle statements (such as group by statement), then you can determine, to that place for the boundaries of the two before and after the stage.
Here we have to Spark the most basic entry procedures - word count to example, how to use the most simple way to roughly calculate a stage corresponding to the code. The following example, in the entire code, only one reduceByKey will happen shuffle operator, so you can think that the operator for the boundaries, will be divided before and after the two stages.
1, stage0, mainly from the implementation of the textFile to map operation, and the implementation of shuffle write operation. Shuffle write operation, we can simply understand the data for pairs RDD in the partition operation, each task processing data, the same key will be written into the same disk file.
2, stage1, mainly from the implementation of the operation from the reduceByKey to collect, stage1 of the various tasks began to run, it will first perform shuffle read operation. The implementation of shuffle read operation of the task, from stage0 each task node to pull their own processing of those keys, and then the same key for a global aggregation or join operations, here is the key value of the cumulative value. Stage1 After executing the implementation of the reduceByKey operator, the final wordCounts RDD is calculated and the collect operator is executed. All the data is drawn to the driver for us to traverse and print the output.
val conf = new SparkConf() val sc = new SparkContext(conf) val lines = sc.textFile("hdfs://...") val words = lines.flatMap(_.split(" ")) val pairs = words.map((_, 1)) val wordCounts = pairs.reduceByKey(_ + _) wordCounts.collect().foreach(println(_))
Through the analysis of the word count program, hoping to let everyone
understand the most basic stage division of the principle, and stage
shuffle operation is how the two stages of the implementation of the
boundary. And then we know how to quickly locate the data tilt of the stage corresponding to which part of the code.
For example, we found in the Spark Web UI or local log, stage1 a few
tasks performed particularly slow to determine the stage1 data tilt,
then you can return to the code to locate the stage1 mainly includes the
reduceByKey the shuffle class operator, At this point the basic can be
determined by the educeByKey operator caused by the data tilt problem.
For example, a word appeared 100 million times, other words only
appeared 10 times, then stage1 a task will deal with 100 million data,
the speed of the stage will be slow down the task. A task inexplicable memory overflow situation
In this case the code to locate the problem is easier. We recommend that you look directly at the exception stack of the local log in the yarn-client mode, or see the exception stack in the log in the yarn-cluster mode by YARN. In general, through the exception stack information can be positioned to your code which line memory overflow occurred. And then find that line of code in the vicinity, there will generally be shuffle class operator, this time it is likely that this operator led to the data tilt.But we should pay attention to is that you can not simply rely on accidental memory overflow to determine the data tilt occurred. Because of their own code to write the bug, as well as accidental data anomalies, may also lead to memory overflow. So in accordance with the above method, through the Spark Web UI to see the report of the stage of the task of the task time and the amount of data allocated to determine whether it is due to data tilt caused the memory overflow.
View the data distribution of the key that caused the data to tilt
Knowing where the data tilt occurs, it is usually necessary to analyze the RDD / Hive table that performed the shuffle operation and cause the data to tilt, and look at the distribution of the key. This is mainly for the subsequent selection of which technical solutions to provide the basis. For different key distribution and different shuffle operators combined with the various circumstances, may need to choose a different technical solutions to solve.At this point according to your operation of the different circumstances, there can be a variety of ways to see the key distribution:
1, if it is Spark SQL group by, join statement caused by the data tilt, then check the SQL used in the table key distribution.
2, if the Spark RDD implementation of the shuffle operator caused by the data tilt, then you can add in the Spark operation to see the key distribution of the code, such as RDD.countByKey (). And then out of the statistics of the number of the emergence of the key, collect / take to the client to print, you can see the distribution of key.
For example, for the word count program described above, if it is determined that the stageB's reduceByKey operator causes data skew, then the key distribution in the RDD for the reduceByKey operation should be looked at. In this example, RDD. In the following example, we can first sample 10% of the sample data, and then use the countByKey operator to count the number of occurrences of each key, and finally in the client traversal and print the sample data in the number of occurrences of each key.
val sampledPairs = pairs.sample(false, 0.1) val sampledWordCounts = sampledPairs.countByKey() sampledWordCounts.foreach(println(_))
Data tilt solution
Solution 1: Use Hive ETL to preprocess the data
Scenario Scenario: The data is tilted by the Hive table. If the data in the Hive table is very heterogeneous (for example, a key corresponds to 1 million data, the other key corresponds to 10 data), and the business scene needs to use Spark frequently perform an analysis operation on the Hive table, then compare Suitable for the use of this technical program.Scenario Implementation: At this point you can assess whether you can use Hive for data preprocessing (that is, the Hive ETL pre-aggregates the data according to the key, or joins with other tables in advance), and then the data for the Spark job The source is not the original Hive table, but the pretreatment of the Hive table. At this point because the data has been pre-polymerization or join operation, then the Spark operation also do not need to use the original shuffle class operator to perform such operations.
Program implementation principle: This solution from the root causes to solve the data tilt, because the Spark in the implementation of the shuffle class operator, then there is certainly no data tilt problem. But here also to remind you that this approach is a temporary solution. Because after all, the data itself there is uneven distribution of the problem, so Hive ETL group by or join shuffle operation, or there will be data tilt, resulting in Hive ETL speed is very slow. We just put the data tilt occurred in advance to the Hive ETL, Spark program to avoid data tilt.
Program advantages: to achieve simple and convenient, the effect is also very good, completely avoid the data tilt, Spark job performance will be greatly improved.
Program shortcomings: temporary solution, Hive ETL or data will occur in the tilt.
Program practice experience: In some Java systems and Spark combination of the use of the project, there will be frequent calls to Spark Queask scene, and the Spark operation performance requirements are very high, it is more suitable for the use of this program. The data is tilted forward to the upstream Hive ETL, only once a day, only then that is relatively slow, and then every time Java calls Spark operations, the implementation speed will be very fast, can provide a better user experience.
Project practice experience: This program is used in the interactive user behavior analysis system of the US group. The system mainly allows the user to submit the data analysis and statistics task through the Java Web system. The back-end is submitted to the Spark operation by Java for data analysis. The Spark operation speed must be fast, as far as possible within 10 minutes, otherwise the speed is too slow, the user experience will be poor. So we will be some Spark operations shuffle operation ahead of the Hive ETL, so that Spark directly using the pretreatment of the Hive intermediate table, as much as possible to reduce Spark's shuffle operation, greatly enhance the performance, part of the performance of the upgrade 6 Times more than.
Solution 2: Filtering a few causes a tilted key
Scenario Applicable Scenario: If you find a few keys that cause tilting, and the impact on the calculation itself is not large, then it is very suitable for the use of this program. Such as 99% of the key corresponds to 10 data, but only one key corresponds to 1 million data, resulting in data tilt.Solution to achieve the idea: If we judge that a small number of data in particular the number of key, the implementation of the operation and the results are not particularly important, then simply filter out a few key directly. For example, in the Spark SQL can use the where clause to filter out the key or in the Spark Core RDD filter operator to filter out the key. If you need to dynamically determine which key data and then filter, you can use the sample operator to sample the RDD, and then calculate the number of each key, the maximum amount of data to filter out the key can.
Program to achieve the principle: the data will lead to tilt the key to filter out, the key will not participate in the calculation, it is impossible to produce data tilt.
Program advantages: to achieve a simple, and the effect is also very good, you can completely avoid the data tilt.
Program shortcomings: the application of the scene is not much, in most cases, leading to the tilt of the key or a lot, not only a few.
Program practice experience: In the project we have also adopted this program to solve the data tilt. Once found a day Spark operation in the run when the sudden OOM, and found after tracing, is a key in the Hive table in the day of data anomalies, resulting in data surge. So to take each time before the implementation of sampling, calculate the maximum amount of data in the sample after a few key, directly in the process of those keys to filter out.
Solution 3: Improve the parallelism of shuffle operations
Scenario Scenario: If we have to lean on the data, it is advisable to use this scheme first because it is the easiest way to handle data skew.Solution implementation : In the implementation of shuffle operator RDD, shuffle operator to pass a parameter, such as reduceByKey (1000), the parameters set the shuffle operator shuffle read task implementation of the number. For Spark SQL in the shuffle class statement, such as group by, join, need to set a parameter, that is, spark.sql.shuffle.partitions, this parameter represents the shuffle read task parallelism, the value of the default is 200, for many scenes It is a bit too small.
Program to achieve the principle: increase the number of shuffle read task, you can make the original assigned to a task multiple assigned to multiple tasks, so that each task to deal with less than the original data. For example, if there are five key, each key corresponds to 10 data, these five keys are assigned to a task, then the task will deal with 50 data. And increase the shuffle read task later, each task is assigned to a key, that is, each task to deal with 10 data, then the natural implementation of each task will be shorter. The specific principles are shown below.
Program advantages: to achieve relatively simple, can effectively alleviate and mitigate the impact of data tilt.
Program shortcomings: just to ease the data tilt it, did not completely eradicate the problem, according to practical experience, its effect is limited.
Program practice experience: the program is usually unable to completely solve the data tilt, because if there are some extreme cases, such as a key corresponding to the amount of data there are 100 million, then no matter how much your task increased to the number of the corresponding 1 million data key Certainly will be assigned to a task to deal with, so destined to still occur data tilt. So this program can only be said to find the data in the tilt when trying to use the first means, try to use the simple way to ease the data tilt, or is combined with other programs used.
Solution 4: Two-stage aggregation (local aggregation + global aggregation)
Scenario Applicable Scenario: This is the case when the aggregation class shuffle operator such as reduceByKey is executed on RDD or grouped by using the group by statement in Spark SQL.Program implementation ideas: the core of this program is the idea of two-stage aggregation. The first time is a local aggregation, give each key are marked with a random number, such as 10 within the random number, then the same as the original key becomes different, such as (hello, 1) (hello, 1) (1_hello, 1) (1_hello, 1) (2_hello, 1) (2_hello, 1) (hello, 1) (hello, 1) (1_hello, 2) (2_hello, 2), then the local aggregation result will be converted to (1_hello, 2) (2_hello, 2), then the local aggregation will be performed by performing the aggregation operation such as reduceByKey. And then the prefix of each key to be removed, it will become (hello, 2) (hello, 2), again global aggregation operation, you can get the final result, such as (hello, 4).
Program to achieve the principle: the original key through the additional random prefix way, into a number of different keys, you can let the original data processing a decentralized to a number of tasks up to do the local aggregation, and then solve a single task processing data Excessive problems. Then remove the random prefix, again global aggregation, you can get the final result. Specific principles see below.
Advantages of the program: the shuffle operation for the aggregation caused by the data tilt, the effect is very good. Usually can solve the data tilt, or at least a significant ease of data tilt, Spark job performance can be improved several times.
Program Disadvantages: only apply to the shuffle operation of the polymerization class, the scope of application is relatively narrow. If the join class shuffle operation, have to use other solutions.

// 第一步,给RDD中的每个key都打上一个随机前缀。 JavaPairRDD<String, Long> randomPrefixRdd = rdd.mapToPair( new PairFunction<Tuple2<Long,Long>, String, Long>() { private static final long serialVersionUID = 1L; @Override public Tuple2<String, Long> call(Tuple2<Long, Long> tuple) throws Exception { Random random = new Random(); int prefix = random.nextInt(10); return new Tuple2<String, Long>(prefix + "_" + tuple._1, tuple._2); } }); // 第二步,对打上随机前缀的key进行局部聚合。 JavaPairRDD<String, Long> localAggrRdd = randomPrefixRdd.reduceByKey( new Function2<Long, Long, Long>() { private static final long serialVersionUID = 1L; @Override public Long call(Long v1, Long v2) throws Exception { return v1 + v2; } }); // 第三步,去除RDD中每个key的随机前缀。 JavaPairRDD<Long, Long> removedRandomPrefixRdd = localAggrRdd.mapToPair( new PairFunction<Tuple2<String,Long>, Long, Long>() { private static final long serialVersionUID = 1L; @Override public Tuple2<Long, Long> call(Tuple2<String, Long> tuple) throws Exception { long originalKey = Long.valueOf(tuple._1.split("_")[1]); return new Tuple2<Long, Long>(originalKey, tuple._2); } }); // 第四步,对去除了随机前缀的RDD进行全局聚合。 JavaPairRDD<Long, Long> globalAggrRdd = removedRandomPrefixRdd.reduceByKey( new Function2<Long, Long, Long>() { private static final long serialVersionUID = 1L; @Override public Long call(Long v1, Long v2) throws Exception { return v1 + v2; } });
Solution 5: Reduce join to map join
Scenario Scenario: When you use the join class for RDD, or when you use the join statement in Spark SQL, and the amount of data for an RDD or table in a join operation is relatively small (for example, several hundred or one or two g) This program.Program implementation ideas: do not use the join operator to connect operations, and the use of Broadcast variables and map class operator to achieve join operation, and thus completely avoid the shuffle class operation, completely avoid the occurrence of data tilt and appear. The data in the smaller RDD is directly passed through the collect operator to the MCU's memory, and then a Broadcast variable is created; then the map class operator is executed on the other RDD. Within the operator function, from the Broadcast variable Get the full amount of RDD data, and the current RDD for each data according to the connection key to match, if the connection key is the same, then the two RDD data you need to connect the way.
Program to achieve the principle: the ordinary join will take the shuffle process, and once shuffle, it is equivalent to the same key data will be pulled to a shuffle read task and then join, this time is reduce join. But if a RDD is relatively small, you can use the broadcast small RDD full data + map operator to achieve the same effect with the join, that is, map join, this time will not happen shuffle operation, it will not occur data tilt The The specific principles are shown below.
Program advantages: the join operation caused by the data tilt, the effect is very good, because there will not be shuffle, it will not happen data tilt.
Program Disadvantages: Applicable to the scene less, because this program only applies to a large table and a small table of the situation. After all, we need to broadcast a small table, this time will be more consumption of memory resources, drivers and each Executor memory will run a small RDD full amount of data. If we broadcast out of the RDD data is relatively large, such as 10G or more, then it may happen memory overflow. So it is not suitable for both large tables.

// 首先将数据量比较小的RDD的数据,collect到Driver中来。 List<Tuple2<Long, Row>> rdd1Data = rdd1.collect() // 然后使用Spark的广播功能,将小RDD的数据转换成广播变量,这样每个Executor就只有一份RDD的数据。 // 可以尽可能节省内存空间,并且减少网络传输性能开销。 final Broadcast<List<Tuple2<Long, Row>>> rdd1DataBroadcast = sc.broadcast(rdd1Data); // 对另外一个RDD执行map类操作,而不再是join类操作。 JavaPairRDD<String, Tuple2<String, Row>> joinedRdd = rdd2.mapToPair( new PairFunction<Tuple2<Long,String>, String, Tuple2<String, Row>>() { private static final long serialVersionUID = 1L; @Override public Tuple2<String, Tuple2<String, Row>> call(Tuple2<Long, String> tuple) throws Exception { // 在算子函数中,通过广播变量,获取到本地Executor中的rdd1数据。 List<Tuple2<Long, Row>> rdd1Data = rdd1DataBroadcast.value(); // 可以将rdd1的数据转换为一个Map,便于后面进行join操作。 Map<Long, Row> rdd1DataMap = new HashMap<Long, Row>(); for(Tuple2<Long, Row> data : rdd1Data) { rdd1DataMap.put(data._1, data._2); } // 获取当前RDD数据的key以及value。 String key = tuple._1; String value = tuple._2; // 从rdd1数据Map中,根据key获取到可以join到的数据。 Row rdd1Value = rdd1DataMap.get(key); return new Tuple2<String, String>(key, new Tuple2<String, Row>(value, rdd1Value)); } }); // 这里得提示一下。 // 上面的做法,仅仅适用于rdd1中的key没有重复,全部是唯一的场景。 // 如果rdd1中有多个相同的key,那么就得用flatMap类的操作,在进行join的时候不能用map,而是得遍历rdd1所有数据进行join。 // rdd2中每条数据都可能会返回多条join后的数据。
Solution 6: Sampling the tilt key and split the join operation
Scenario Applicable Scenario: When two RDD / Hive tables are joined, if the amount of data is large, you can not use "Solution 5", then you can look at the two RDD / Hive table in the key distribution. If the data is tilted, because the data volume of the few keys in one of the RDD / Hive tables is too large and all the keys in the other RDD / Hive table are evenly distributed, it is appropriate to use this solution of.Program to achieve ideas:
1, on the inclusion of a small number of data over the key of the RDD, through the sample operator to sample a sample, and then statistics about the number of each key, calculated the largest amount of data which is the number of key.
2, and then these key corresponding to the data from the original RDD split out to form a separate RDD, and each key are marked with n within the random number as a prefix, and will not lead to the tilt of most of the key Form another RDD.
3, then the need to join another RDD, but also filter out a few tilt key corresponding to the data and the formation of a separate RDD, each data expansion into n data, which n data in order to attach a 0 ~ The prefix of n does not cause the tilt of most of the keys to also form another RDD.
4, and then add a random prefix of the independent RDD and another expansion of n times the independent RDD join, this time you can be the same key to break up into n, scattered to multiple tasks to join.
5, while the other two ordinary RDD can join as usual.
6, and finally the results of the two join using union operator can be combined, that is, the final join results.
Program implementation principle : For the data caused by the tilt of the join, if only a few key lead to the tilt, you can split a few key into an independent RDD, and add a random prefix to break up to n to join, this time A key corresponding to the data will not focus on a few tasks, but distributed to multiple tasks for the join. Specific principles see below.
Advantages of the program: the data caused by the tilt of the join, if only a few key led to the tilt, the use of the way you can use the most effective way to break up the key to join. And only need for a small number of tilt key corresponding to the data expansion n times, do not need to expand the full amount of data. To avoid taking up too much memory.
Solution Disadvantages: If the resulting key is particularly tilted, such as thousands of keys are leading to data tilt, then this approach is not suitable.

// 首先从包含了少数几个导致数据倾斜key的rdd1中,采样10%的样本数据。 JavaPairRDD<Long, String> sampledRDD = rdd1.sample(false, 0.1); // 对样本数据RDD统计出每个key的出现次数,并按出现次数降序排序。 // 对降序排序后的数据,取出top 1或者top 100的数据,也就是key最多的前n个数据。 // 具体取出多少个数据量最多的key,由大家自己决定,我们这里就取1个作为示范。 JavaPairRDD<Long, Long> mappedSampledRDD = sampledRDD.mapToPair( new PairFunction<Tuple2<Long,String>, Long, Long>() { private static final long serialVersionUID = 1L; @Override public Tuple2<Long, Long> call(Tuple2<Long, String> tuple) throws Exception { return new Tuple2<Long, Long>(tuple._1, 1L); } }); JavaPairRDD<Long, Long> countedSampledRDD = mappedSampledRDD.reduceByKey( new Function2<Long, Long, Long>() { private static final long serialVersionUID = 1L; @Override public Long call(Long v1, Long v2) throws Exception { return v1 + v2; } }); JavaPairRDD<Long, Long> reversedSampledRDD = countedSampledRDD.mapToPair( new PairFunction<Tuple2<Long,Long>, Long, Long>() { private static final long serialVersionUID = 1L; @Override public Tuple2<Long, Long> call(Tuple2<Long, Long> tuple) throws Exception { return new Tuple2<Long, Long>(tuple._2, tuple._1); } }); final Long skewedUserid = reversedSampledRDD.sortByKey(false).take(1).get(0)._2; // 从rdd1中分拆出导致数据倾斜的key,形成独立的RDD。 JavaPairRDD<Long, String> skewedRDD = rdd1.filter( new Function<Tuple2<Long,String>, Boolean>() { private static final long serialVersionUID = 1L; @Override public Boolean call(Tuple2<Long, String> tuple) throws Exception { return tuple._1.equals(skewedUserid); } }); // 从rdd1中分拆出不导致数据倾斜的普通key,形成独立的RDD。 JavaPairRDD<Long, String> commonRDD = rdd1.filter( new Function<Tuple2<Long,String>, Boolean>() { private static final long serialVersionUID = 1L; @Override public Boolean call(Tuple2<Long, String> tuple) throws Exception { return !tuple._1.equals(skewedUserid); } }); // rdd2,就是那个所有key的分布相对较为均匀的rdd。 // 这里将rdd2中,前面获取到的key对应的数据,过滤出来,分拆成单独的rdd,并对rdd中的数据使用flatMap算子都扩容100倍。 // 对扩容的每条数据,都打上0~100的前缀。 JavaPairRDD<String, Row> skewedRdd2 = rdd2.filter( new Function<Tuple2<Long,Row>, Boolean>() { private static final long serialVersionUID = 1L; @Override public Boolean call(Tuple2<Long, Row> tuple) throws Exception { return tuple._1.equals(skewedUserid); } }).flatMapToPair(new PairFlatMapFunction<Tuple2<Long,Row>, String, Row>() { private static final long serialVersionUID = 1L; @Override public Iterable<Tuple2<String, Row>> call( Tuple2<Long, Row> tuple) throws Exception { Random random = new Random(); List<Tuple2<String, Row>> list = new ArrayList<Tuple2<String, Row>>(); for(int i = 0; i < 100; i++) { list.add(new Tuple2<String, Row>(i + "_" + tuple._1, tuple._2)); } return list; } }); // 将rdd1中分拆出来的导致倾斜的key的独立rdd,每条数据都打上100以内的随机前缀。 // 然后将这个rdd1中分拆出来的独立rdd,与上面rdd2中分拆出来的独立rdd,进行join。 JavaPairRDD<Long, Tuple2<String, Row>> joinedRDD1 = skewedRDD.mapToPair( new PairFunction<Tuple2<Long,String>, String, String>() { private static final long serialVersionUID = 1L; @Override public Tuple2<String, String> call(Tuple2<Long, String> tuple) throws Exception { Random random = new Random(); int prefix = random.nextInt(100); return new Tuple2<String, String>(prefix + "_" + tuple._1, tuple._2); } }) .join(skewedUserid2infoRDD) .mapToPair(new PairFunction<Tuple2<String,Tuple2<String,Row>>, Long, Tuple2<String, Row>>() { private static final long serialVersionUID = 1L; @Override public Tuple2<Long, Tuple2<String, Row>> call( Tuple2<String, Tuple2<String, Row>> tuple) throws Exception { long key = Long.valueOf(tuple._1.split("_")[1]); return new Tuple2<Long, Tuple2<String, Row>>(key, tuple._2); } }); // 将rdd1中分拆出来的包含普通key的独立rdd,直接与rdd2进行join。 JavaPairRDD<Long, Tuple2<String, Row>> joinedRDD2 = commonRDD.join(rdd2); // 将倾斜key join后的结果与普通key join后的结果,uinon起来。 // 就是最终的join结果。 JavaPairRDD<Long, Tuple2<String, Row>> joinedRDD = joinedRDD1.union(joinedRDD2);
Solution 7: Use random prefix and expansion RDD for join
Scenario Applicable Scenario: If there is a large amount of key in the RDD that causes the data to be tilted when the join operation is performed, then the split key is meaningless, and only the last scenario is used to solve the problem.Program to achieve ideas:
1, the implementation of the program ideas and "solution six" similar to the first look at the RDD / Hive table data distribution, find that data caused by the tilt of the RDD / Hive table, such as multiple keys are corresponding to more than 1 million Article data.
2, and then the RDD of each data are marked with a random prefix within n.
3, while another normal RDD expansion, each data are expanded into n data, the expansion of each data are followed by a 0 ~ n prefix.
4, the last two after the RDD can join.
Program to achieve the principle: the original key through the additional random prefix into a different key, and then these can be processed after the "different key" to a number of tasks to deal with, rather than a task to deal with a large number of the same Key. The difference between the scheme and "solution six" is that the last solution is to treat the data corresponding to a small number of slanted keys as much as possible. Since the process needs to expand RDD, the latter scheme expands RDD to memory Of the occupation is not large; and this kind of program is for a large number of tilt key situation, can not be part of the key split out separately for processing, so only the entire RDD data expansion, the memory resource requirements are high.
Program advantages: the join type of data tilt can be basically the basic treatment, and the effect is relatively significant, performance improvement effect is very good.
Program Disadvantages: The program is more to ease the data tilt, rather than completely avoid data tilt.And the need for expansion of the entire RDD, memory resource demanding.
Program experience: have developed a data needs, they found a lead to join the data skew. Prior to optimization, the job execution time is about 60 minutes; then optimized using this program, the execution time is shortened to about 10 minutes, 6-fold increase in performance.
// 首先将其中一个key分布相对较为均匀的RDD膨胀100倍。 JavaPairRDD<String, Row> expandedRDD = rdd1.flatMapToPair( new PairFlatMapFunction<Tuple2<Long,Row>, String, Row>() { private static final long serialVersionUID = 1L; @Override public Iterable<Tuple2<String, Row>> call(Tuple2<Long, Row> tuple) throws Exception { List<Tuple2<String, Row>> list = new ArrayList<Tuple2<String, Row>>(); for(int i = 0; i < 100; i++) { list.add(new Tuple2<String, Row>(0 + "_" + tuple._1, tuple._2)); } return list; } }); // 其次,将另一个有数据倾斜key的RDD,每条数据都打上100以内的随机前缀。 JavaPairRDD<String, String> mappedRDD = rdd2.mapToPair( new PairFunction<Tuple2<Long,String>, String, String>() { private static final long serialVersionUID = 1L; @Override public Tuple2<String, String> call(Tuple2<Long, String> tuple) throws Exception { Random random = new Random(); int prefix = random.nextInt(100); return new Tuple2<String, String>(prefix + "_" + tuple._1, tuple._2); } }); // 将两个处理后的RDD进行join即可。 JavaPairRDD<String, Tuple2<String, Row>> joinedRDD = mappedRDD.join(expandedRDD);
Solution eight: a combination of a variety of programs
I found in practice that, in many cases, if only relatively simple processing data skew scenario, then use one of the above-described embodiment can be basically solved. However, if a more complex to handle data skew scenario, it may be desirable to use a combination of a variety of programs. For example, we focused on the emergence of multiple data links tilt Spark job, you can use the solution I and II, part of the data pre-processing and filtering to alleviate some of the data; Second, can enhance the degree of parallelism for certain shuffle operation, optimize its performance; Finally, also for different polymeric or join operation to select a solution to optimize its performance. Then we need to ideas and principles of these programs have a thorough understanding, in practice, according to a variety of different situations, flexible use of a variety of programs to solve their own data skew problem.
This article was reproduced from : http://tech.meituan.com/spark-tuning-pro.html



Commentaires
Enregistrer un commentaire