Spark through the BulkLoad quickly on the massive data into the Hbase
We introduced
a quick way to import massive amounts of data into Hbase by introducing
bulk data into Hbase [Hadoop articles] through BulkLoad . This article will show you how to use Scala to quickly import data into Springs Methods. Here are two ways: the first to use Put ordinary method to count down; the second use Bulk Load API. For more information on why you need to use Bulk Load This article is not introduced , see "BulkLoad quickly into the massive data into Hbase [Hadoop articles]" .
If you want to keep abreast of Spark , Hadoop or Hbase related articles, please pay attention to WeChat public account: iteblog_hadoop
(2), direct import of data into the Hbase.
(1), Mr. Hfiles;
(2), use
The implementation code is as follows:
After running the above code, we can see that the itblog table in the Hbase has generated 10 data, as follows:
will
changed to:
The complete implementation is as follows:
changed to
The rest is exactly the same as before.
If you want to keep abreast of Spark , Hadoop or Hbase related articles, please pay attention to WeChat public account: iteblog_hadoop
Article directory
Use org.apache.hadoop.hbase.client.Put to write data
Useorg.apache.hadoop.hbase.client.Put to write data one by one to the Hbase, but it is org.apache.hadoop.hbase.client.Put than Bulk loading, just as a contrast. import org.apache.spark._import org.apache.spark.rdd.NewHadoopRDDimport org.apache.hadoop.hbase.{HBaseConfiguration, HTableDescriptor}import org.apache.hadoop.hbase.client.HBaseAdminimport org.apache.hadoop.hbase.mapreduce.TableInputFormatimport org.apache.hadoop.fs.Path;import org.apache.hadoop.hbase.HColumnDescriptorimport org.apache.hadoop.hbase.util.Bytesimport org.apache.hadoop.hbase.client.Put;import org.apache.hadoop.hbase.client.HTable; val conf = HBaseConfiguration.create()val tableName = "/iteblog"conf.set(TableInputFormat.INPUT_TABLE, tableName) val myTable = new HTable(conf, tableName);var p = new Put();p = new Put(new String("row999").getBytes());p.add("cf".getBytes(), "column_name".getBytes(), new String("value999").getBytes());myTable.put(p);myTable.flushCommits(); |
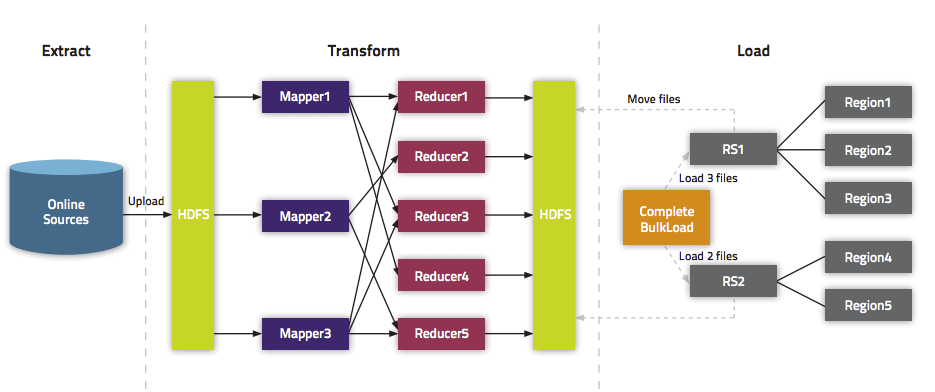
Batch guide to Hbase
Batch guide data to the Hbase can be divided into two kinds: (1), generate Hfiles, and then batch guide data;(2), direct import of data into the Hbase.
Bulk imports Hfiles into Hbase
Now we have to introduce how to batch data into the Hbase, mainly divided into two steps:(1), Mr. Hfiles;
(2), use
org.apache.hadoop.hbase.mapreduce.LoadIncrementalHFiles to import Hfiles into Hbase in advance. The implementation code is as follows:
import org.apache.spark._import org.apache.spark.rdd.NewHadoopRDDimport org.apache.hadoop.hbase.{HBaseConfiguration, HTableDescriptor}import org.apache.hadoop.hbase.client.HBaseAdminimport org.apache.hadoop.hbase.mapreduce.TableInputFormatimport org.apache.hadoop.fs.Path;import org.apache.hadoop.hbase.HColumnDescriptorimport org.apache.hadoop.hbase.util.Bytesimport org.apache.hadoop.hbase.client.Put;import org.apache.hadoop.hbase.client.HTable;import org.apache.hadoop.hbase.mapred.TableOutputFormatimport org.apache.hadoop.mapred.JobConfimport org.apache.hadoop.hbase.io.ImmutableBytesWritableimport org.apache.hadoop.mapreduce.Jobimport org.apache.hadoop.mapreduce.lib.input.FileInputFormatimport org.apache.hadoop.mapreduce.lib.output.FileOutputFormatimport org.apache.hadoop.hbase.KeyValueimport org.apache.hadoop.hbase.mapreduce.HFileOutputFormatimport org.apache.hadoop.hbase.mapreduce.LoadIncrementalHFiles val conf = HBaseConfiguration.create()val tableName = "iteblog"val table = new HTable(conf, tableName) conf.set(TableOutputFormat.OUTPUT_TABLE, tableName)val job = Job.getInstance(conf)job.setMapOutputKeyClass (classOf[ImmutableBytesWritable])job.setMapOutputValueClass (classOf[KeyValue])HFileOutputFormat.configureIncrementalLoad (job, table) // Generate 10 sample data:val num = sc.parallelize(1 to 10)val rdd = num.map(x=>{ val kv: KeyValue = new KeyValue(Bytes.toBytes(x), "cf".getBytes(), "c1".getBytes(), "value_xxx".getBytes() ) (new ImmutableBytesWritable(Bytes.toBytes(x)), kv)}) // Save Hfiles on HDFS rdd.saveAsNewAPIHadoopFile("/tmp/iteblog", classOf[ImmutableBytesWritable], classOf[KeyValue], classOf[HFileOutputFormat], conf) //Bulk load Hfiles to Hbaseval bulkLoader = new LoadIncrementalHFiles(conf)bulkLoader.doBulkLoad(new Path("/tmp/iteblog"), table) |
hbase(main):020:0> scan 'iteblog'ROW COLUMN+CELL \x00\x00\x00\x01 column=cf:c1, timestamp=1425128075586, value=value_xxx \x00\x00\x00\x02 column=cf:c1, timestamp=1425128075586, value=value_xxx \x00\x00\x00\x03 column=cf:c1, timestamp=1425128075586, value=value_xxx \x00\x00\x00\x04 column=cf:c1, timestamp=1425128075586, value=value_xxx \x00\x00\x00\x05 column=cf:c1, timestamp=1425128075586, value=value_xxx \x00\x00\x00\x06 column=cf:c1, timestamp=1425128075675, value=value_xxx \x00\x00\x00\x07 column=cf:c1, timestamp=1425128075675, value=value_xxx \x00\x00\x00\x08 column=cf:c1, timestamp=1425128075675, value=value_xxx \x00\x00\x00\x09 column=cf:c1, timestamp=1425128075675, value=value_xxx \x00\x00\x00\x0A column=cf:c1, timestamp=1425128075675, value=value_xxx |
Direct Bulk Load data to Hbase
This method does not need to generate Hfiles on HDFS in advance, but directly to the bulk of the data into the Hbase. There are only minor differences compared to the above example, as follows:will
rdd.saveAsNewAPIHadoopFile("/tmp/iteblog", classOf[ImmutableBytesWritable], classOf[KeyValue], classOf[HFileOutputFormat], conf) |
rdd.saveAsNewAPIHadoopFile("/tmp/iteblog", classOf[ImmutableBytesWritable], classOf[KeyValue], classOf[HFileOutputFormat], job.getConfiguration()) |
import org.apache.spark._import org.apache.spark.rdd.NewHadoopRDDimport org.apache.hadoop.hbase.{HBaseConfiguration, HTableDescriptor}import org.apache.hadoop.hbase.client.HBaseAdminimport org.apache.hadoop.hbase.mapreduce.TableInputFormatimport org.apache.hadoop.fs.Path;import org.apache.hadoop.hbase.HColumnDescriptorimport org.apache.hadoop.hbase.util.Bytesimport org.apache.hadoop.hbase.client.Put;import org.apache.hadoop.hbase.client.HTable;import org.apache.hadoop.hbase.mapred.TableOutputFormatimport org.apache.hadoop.mapred.JobConfimport org.apache.hadoop.hbase.io.ImmutableBytesWritableimport org.apache.hadoop.mapreduce.Jobimport org.apache.hadoop.mapreduce.lib.input.FileInputFormatimport org.apache.hadoop.mapreduce.lib.output.FileOutputFormatimport org.apache.hadoop.hbase.KeyValueimport org.apache.hadoop.hbase.mapreduce.HFileOutputFormatimport org.apache.hadoop.hbase.mapreduce.LoadIncrementalHFiles val conf = HBaseConfiguration.create()val tableName = "iteblog"val table = new HTable(conf, tableName) conf.set(TableOutputFormat.OUTPUT_TABLE, tableName)val job = Job.getInstance(conf)job.setMapOutputKeyClass (classOf[ImmutableBytesWritable])job.setMapOutputValueClass (classOf[KeyValue])HFileOutputFormat.configureIncrementalLoad (job, table) // Generate 10 sample data:val num = sc.parallelize(1 to 10)val rdd = num.map(x=>{ val kv: KeyValue = new KeyValue(Bytes.toBytes(x), "cf".getBytes(), "c1".getBytes(), "value_xxx".getBytes() ) (new ImmutableBytesWritable(Bytes.toBytes(x)), kv)}) // Directly bulk load to Hbase/MapRDB tables.rdd.saveAsNewAPIHadoopFile("/tmp/iteblog", classOf[ImmutableBytesWritable], classOf[KeyValue], classOf[HFileOutputFormat], job.getConfiguration()) |
other
In the above example, we used thesaveAsNewAPIHadoopFile API to write data to HBase; in fact, we can also use the saveAsNewAPIHadoopDataset API to achieve the same goal, we only need to the saveAsNewAPIHadoopDataset code rdd.saveAsNewAPIHadoopFile("/tmp/iteblog", classOf[ImmutableBytesWritable], classOf[KeyValue], classOf[HFileOutputFormat], job.getConfiguration()) |
job.getConfiguration.set("mapred.output.dir", "/tmp/iteblog")rdd.saveAsNewAPIHadoopDataset(job.getConfiguration) |



It was really a nice article and i was really impressed by reading this Big Data Hadoop Online Course
RépondreSupprimer