Apache Spark : RDD vs DataFrame vs Dataset

With Spark2.0 release, there are 3 types of data
abstractions which Spark officially provides now to use : RDD,DataFrame
and DataSet .
For a new user, it might be confusing to understand
relevance of each one and decide which one to use and which one not to.
In this post, will discuss each one of them in detail with their
differences and pros-cons.
Short Combined Intro :
Before i discuss each one in detail separately, want to start with a short combined intro.
Evolution of these abstractions happened in this way :
RDD (Spark1.0) —> Dataframe(Spark1.3) —> Dataset(Spark1.6)
RDD being the oldest available from 1.0 version to Dataset being the newest available from 1.6 version.
Given same data, each of the 3 abstraction will compute
and give same results to user. But they differ in performance and the
ways they compute.
RDD lets us decide HOW
we want to do which limits the optimisation Spark can do on processing
underneath where as dataframe/dataset lets us decide WHAT we want to do
and leave everything on Spark to decide how to do computation.
We will understand this in 2 minutes what is meant by HOW & WHAT .
Dataframe came as a major performance improvement over RDD but not without some downsides.
This led to development of Dataset which is an effort to unify best of RDD and data frame.
In future, Dataset will eventually replace RDD and Dataframe to become the only API spark users should be using in code.
Lets understand them in detail one by one.
RDD:
-Its building block of spark. No matter which
abstraction Dataframe or Dataset we use, internally final computation is
done on RDDs.
-RDD is lazily evaluated immutable parallel collection of objects exposed with lambda functions.
-The best part about RDD is that it is simple. It
provides familiar OOPs style APIs with compile time safety. We can load
any data from a source,convert them into RDD and store in memory to
compute results. RDD can be easily cached if same set of data needs to
recomputed.
-But the disadvantage is performance limitations. Being
in-memory jvm objects, RDDs involve overhead of Garbage Collection and
Java(or little better Kryo) Serialisation which are expensive when data
grows.
RDD example:

Dataframe:
-DataFrame is an abstraction which gives a schema view
of data. Which means it gives us a view of data as columns with column
name and types info, We can think data in data frame like a table in
database.
-Like RDD, execution in Dataframe too is lazy triggered .
-offers huge performance improvement over RDDs because of 2 powerful features it has:
1. Custom Memory management (aka Project Tungsten)
Data is stored in
off-heap memory in binary format. This saves a lot of memory space. Also
there is no Garbage Collection overhead involved. By knowing the schema
of data in advance and storing efficiently in binary format, expensive
java Serialization is also avoided.
2. Optimized Execution Plans (aka Catalyst Optimizer)
Query plans are created for execution using
Spark catalyst optimiser. After an optimised execution plan is prepared
going through some steps, the final execution happens internally on RDDs
only but thats completely hidden from the users.
 |
| Execution plan stages |
Just to give an example of optimisation with respect to the above picture, lets consider a query as below :
 |
| inefficient query: filter after join |
 |
| optimization at run time during execution |
In the above query, filter is used before join which is
a costly shuffle operation. The logical plan sees that and in optimised
logical plan, this filter is pushed to execute before join. In the
optimised execution plan, it can leverage datasource capabilities also
and push that filter further down to datasource so that it can apply
that filter on the disk level rather than bringing all data in memory
and doing filter in memory (which is not possible while directly using
RDDs). So filter method now effectively works like a WHERE clause in a
database query. Also with optimised data sources like parquet , if Spark
sees that you need only few columns to compute the results , it will
read and fetch only those columns from parquet saving both disk IO and
memory.
-Drawback : Lack of Type Safety. As a developer, i will
not like using dataframe as it doesn't seem developer friendly.
Referring attribute by String names means no compile time safety. Things
can fail at runtime. Also APIs doesn't look programmatic and more of
sql kind.
Dataframe example:
2 ways to define: 1. Expression BuilderStyle 2. SQL Style

As discussed, If we try using some columns not present
in schema, we will get problem only at runtime . For example, if we try
accessing salary when only name and age are present in the schema will
exception like below:

Dataset:
-It is an extension to Dataframe API, the latest abstraction which tries to provide best of both RDD and Dataframe.
-comes with OOPs style and developer friendly compile
time safety like RDD as well as performance boosting features of
Dataframe : Catalyst optimiser and custom memory management.
-How dataset scores over Dataframe is an additional feature it has: Encoders .
-Encoders act as interface between JVM objects and off-heap custom memory binary format data.
-Encoders generate byte code to interact with off-heap
data and provide on-demand access to individual attributes without
having to de-serialize an entire object.
-case class is used to define the structure of
data schema in Dataset. Using case class, its very easy to work with
dataset. Names of different attributes in case class is directly mapped
to attributes in Dataset . It gives feeling like working with RDD but
actually underneath it works same as Dataframe.
Dataframe is infact treated as dataset of generic row objects. DataFrame=Dataset[Row] . So we can always convert a data frame at any point of time into a dataset by calling ‘as’ method on Dataframe.
e.g. df.as[MyClass]
e.g. df.as[MyClass]
Dataset Example :
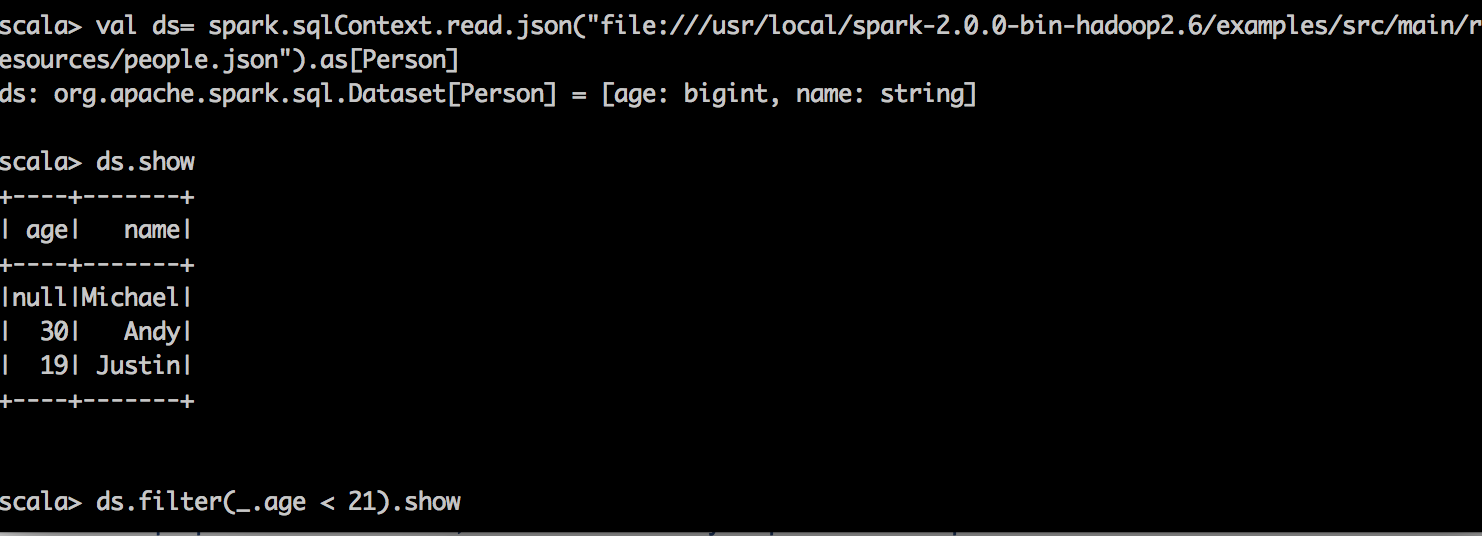
Important point to remember
is that both Dataset and DataFrame internally does final execution on
RDD objects only but the difference is users do not write code to create
the RDD collections and have no control as such over RDDs. RDDs are
created in the execution plan as last stage after deciding and going
through all the optimizations (see Execution Plan Diagram).
Thats why at the beginning of this post i emphasized on……..RDD let us decide HOW we want to do where as Dataframe/Dataset lets us decide WHAT we want to do.
And all these optimisations could have been possible
because data is structured and Spark knows about the schema of data in
advance. So it can apply all the powerful features like tungsten custom
memory off-heap binary storage,catalyst optimiser and encoders to get
the performance which was not possible if users would have been directly
working on RDD.
Conclusion:
In short, Spark is moving from unstructured
computation(RDDs) towards structured computation because of many
performance optimisations it allows . Data frame was a step in direction
of structured computation but lacked developer friendliness of compile
time safety,lambda functions. Finally Dataset is the unification of
Dataframe and RDD to bring the best abstraction out of two.
Going forward developers should only be concerned about
DataSet while Dataframe and RDD will be discouraged to use. But its
always better to be aware of the legacy for better understanding of
internals.
Interestingly,most of these new concepts like custom
memory management(tungsten),logical/physical plans(catalyst
optimizer),encoders(dataset),etc seems to be inspired from its
competitor Apache Flink which inherently supports these since
inception.There are other new powerful feature enhancements like
windowing,sessions,etc coming in Spark which are already in Flink. So
its better to keep a close watch on both Spark and Flink in coming days.
Meanwhile i would recommend to :
1. watch this excellent talk from Spark summit on dataframe and dataset : https://www.youtube.com/watch?v=1a4pgYzeFwE
2.read this post from data bricks blog : https://databricks.com/blog/2016/07/14/a-tale-of-three-apache-spark-apis-rdds-dataframes-and-datasets.html
References:
https://www.youtube.com/watch?v=pZQsDloGB4w
References:
https://www.youtube.com/watch?v=pZQsDloGB4w



I like your post very much. It is very much useful for my research. I hope you to share more info about this. Keep posting Apache Spark Training
RépondreSupprimer