API. Spark SQL 1.3.0 DataFrame introduced, used and provided some complete data write
Application Programming Interface Is the meaning of the application interface API is the cornerstone of the system is Windows brick and tile. Clear a concept, the software is running on the support of the system platform, the software function is actually extended to the system, and by the system to complete these functions of the process. Then the software to do things how to pass to the system, that is, the role of these APIs, the system defines these API functions, as the software to support the implementation of system functions interface.
In a word is a function. For example, you have written a class, this class has a lot of functions, if someone else to use your class, but do not know how each function is achieved, it is only know that the function of the entry parameters and return value or only Know that this function is used for what the user is your function is the API, that is, you write the API, the same, windows api is written by some of the functions of Microsoft. API (Application Programming Interface) is a pre-defined function, the purpose is to provide applications and developers based on a software or hardware to access a set of routines
This question you should read, do not understand that you need to see more of the other areas of the book ... Application interface, is the agreement between different systems or different components ... important is the agreement, API is not necessarily the code ... E.g... I wrote a program, and then tell the caller, you want to reference a file and then call a function is to achieve a function, which is API ...
I write a program, and then tell the caller, you just press me to give you a format to read and write a text file can achieve a function, which is API ...
Landlord actually asked a very good question. We often ignore the most common business of work and life.
In fact, the API is the software to develop the function to access the interface, but not that is an interface must be API. I think the API is often the following features: 1) in the system is the outermost interface, is for the user to directly call; 2) stability: If the system interface often become, the user must be crazy; 3) 4) multi-form: refers to the API can be used for java export, to provide the form of the library can also be accessed through the way REST and so on.... Is the function interface. It is clear that the definition of a good function, you can directly used to complete your function. For example, the mathematical function of the absolute value of the abs ();
Http://www.aboutyun.com/forum.php?mod=viewthread&tid=12358&page=1
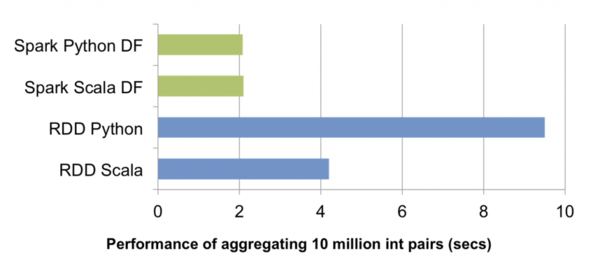
Question guide 1. What is the DataFrame? 2. How do I create a DataFrame? 3. How to convert an ordinary RDD to a DataFrame? 4. How do I use a DataFrame? 5. What are the complete data write support APIs provided in 1.3.0? Since March 2013, Spark SQL has become the largest Spark component other than Spark Core. In addition to taking over Shark's baton and continuing to provide high-performance SQL on Hadoop solutions for Spark users, it also provides Spark with a versatile, efficient and multi-disciplined structured data processing capability. In the recently released version 1.3.0, Spark SQL two upgrades were interpreted most vividly.DataFrameFor ease of use, compared to the traditional MapReduce API, said Spark's RDD API has an infinite leap in the past is not an exaggeration. However, for those who do not have MapReduce and functional programming experience, the RDD API still has a certain threshold. On the other hand, data scientists are familiar with the R, Pandas and other traditional data framework, although providing an intuitive API, but limited to stand-alone processing, can not do big data scene. In order to solve this contradiction, Spark SQL 1.3.0 in the original SchemaRDD based on the R and Pandas style similar to the DataFrame API. The new DataFrame API not only significantly reduces the learning threshold for regular developers, but also supports Scala, Java and Python in three languages. More importantly, due to self-extracting from SchemaRDD, DataFrame is naturally applicable to distributed large data scenes.What is the DataFrame?In Spark, DataFrame is an RDD-based distributed data set, similar to the traditional database in the two-dimensional form. The main difference between a DataFrame and RDD is that the former has schema metadata, that is, each column of a two-dimensional table dataset represented by a DataFrame has a name and a type. This allows the Spark SQL to gain insight into the structure of the information, so as to hide behind the DataFrame data source and the role of the DataFrame on the transformation of the targeted optimization, and ultimately achieve a substantial increase in operational efficiency goals. In contrast, RBC, because there is no way to know the specific internal structure of the stored data elements, Spark Core only at the stage level for simple, common pipeline optimization.Create a DataFrameIn Spark SQL, developers can easily convert various internal and external standalone, distributed data to DataFrame. The following Python sample code fully demonstrates the richness and ease of use of DataFrame data sources in Spark SQL 1.3.0:Visible, from the Hive table to the external data source API support for a variety of data sources (JSON, Parquet, JDBC), and then to the RDD and even a variety of local data sets, can be quickly and easily loaded, converted to DataFrame. These features also exist in Spark SQL's Scala API and Java API.Use a DataFrameSimilar to R, Pandas, Spark DataFrame also provides a complete set of DSL for manipulating data. These DSLs are semantically similar to SQL query queries (which is one of the important reasons why Spark SQL can provide seamless support for DataFrame). The following is an example of a set of user data analysis:In addition to DSL, we can of course, as usual, with SQL to deal with DataFrame:Finally, when the data analysis logic is written, we can save the final result or show it:Behind the scenes: Spark SQL query optimizer with code generationJust as the various transformations of RDD are actually just constructing RDD DAG, various transformations of DataFrame are also lazy. They do not directly calculate the results, but will be assembled into a variety of transformations and RDD DAG similar to the logical query plan. As mentioned earlier, because the DataFrame with schema meta information, Spark SQL query optimizer to insight into the data and the calculation of the fine structure, so the implementation of a highly targeted optimization. Subsequently, the optimized logic execution plan was translated into a physical execution plan and eventually implemented as RDD DAG.The benefits of doing so are reflected in several aspects:1. The user can use fewer declarative code to clarify the calculation logic, the physical execution path is selected by Spark SQL. On the one hand to reduce the development costs, on the one hand also reduces the use of the threshold - in many cases, even if the novice to write a more inefficient query, Spark SQL can also push the conditions of push, column pruning and other strategies to be effectively optimized. This is not available in the RDD API.2. Spark SQL can dynamically generate JVM bytecode for the expression in the physical execution plan, further implement the virtual function call overhead, reduce the number of object allocation and other underlying optimization, so that the final query execution performance can be related to the performance of handwritten code Comparable.3. For PySpark, the use of DataFrame programming only need to build a small logical execution plan, the physical implementation of all by the JVM side responsible for the Python interpreter and JVM between a large number of unnecessary cross-process communication can be removed. As shown in the figure above, a simple set of tests on the aggregation of 10 million integers to PySpark, the performance of the DataFrame API, is nearly five times faster than the RDD API. In addition, PySpark can benefit from Spark SQL's performance improvements to the query optimizer at Scala.External data source API enhancementsFrom the previous text we have seen, Spark 1.3.0 for DataFrame provides a wealth of data source support. One of the highlights is the external data source API introduced by Spark 1.2.0. In 1.3.0, we have further enhanced this API.Data write supportIn Spark 1.2.0, the external data source API can only read data from external data sources into Spark, and can not write the results back to the data source. At the same time, the tables imported and registered through the data source can only be temporary tables, Relevant meta information can not be persisted. In 1.3.0, we provide complete data write support, which complements the last piece of important puzzle for multiple data source interoperability. In the previous example, Hive, Parquet, JSON, Pandas and other data sources between the arbitrary conversion, it is the direct result of this enhancement.At the perspective of Spark SQL external data source developers, the data written to support APIs mainly include:1. Data source table metadata is persistent1.3.0 introduces a new external data source DDL syntax (SQL code snippet)Thus, the SQL tables registered from external data can be either temporary tables or persistent to Hive metastore. In addition to the need to inherit the original RelationProvider, but also need to inherit CreatableRelationProvider.2. InsertableRelationSupport the data to write the external data source of the relation class, need to inherit trait InsertableRelation, and insert method to achieve data insertion logic.The built-in JSON and Parquet data sources in Spark 1.3.0 have implemented the API described above and can serve as a reference example for developing an external data source.Uniform load / save APIIn Spark 1.2.0, in order to preserve the results in SchemaRDD, the choice is not much more convenient. Some of the commonly used include:
Since March 2013, Spark SQL has become the largest Spark component other than Spark Core. In addition to taking over Shark's baton and continuing to provide high-performance SQL on Hadoop solutions for Spark users, it also provides Spark with a versatile, efficient and multi-disciplined structured data processing capability. In the recently released version 1.3.0, Spark SQL two upgrades were interpreted most vividly.DataFrameFor ease of use, compared to the traditional MapReduce API, said Spark's RDD API has an infinite leap in the past is not an exaggeration. However, for those who do not have MapReduce and functional programming experience, the RDD API still has a certain threshold. On the other hand, data scientists are familiar with the R, Pandas and other traditional data framework, although providing an intuitive API, but limited to stand-alone processing, can not do big data scene. In order to solve this contradiction, Spark SQL 1.3.0 in the original SchemaRDD based on the R and Pandas style similar to the DataFrame API. The new DataFrame API not only significantly reduces the learning threshold for regular developers, but also supports Scala, Java and Python in three languages. More importantly, due to self-extracting from SchemaRDD, DataFrame is naturally applicable to distributed large data scenes.What is the DataFrame?In Spark, DataFrame is an RDD-based distributed data set, similar to the traditional database in the two-dimensional form. The main difference between a DataFrame and RDD is that the former has schema metadata, that is, each column of a two-dimensional table dataset represented by a DataFrame has a name and a type. This allows the Spark SQL to gain insight into the structure of the information, so as to hide behind the DataFrame data source and the role of the DataFrame on the transformation of the targeted optimization, and ultimately achieve a substantial increase in operational efficiency goals. In contrast, RBC, because there is no way to know the specific internal structure of the stored data elements, Spark Core only at the stage level for simple, common pipeline optimization.Create a DataFrameIn Spark SQL, developers can easily convert various internal and external standalone, distributed data to DataFrame. The following Python sample code fully demonstrates the richness and ease of use of DataFrame data sources in Spark SQL 1.3.0:Visible, from the Hive table to the external data source API support for a variety of data sources (JSON, Parquet, JDBC), and then to the RDD and even a variety of local data sets, can be quickly and easily loaded, converted to DataFrame. These features also exist in Spark SQL's Scala API and Java API.Use a DataFrameSimilar to R, Pandas, Spark DataFrame also provides a complete set of DSL for manipulating data. These DSLs are semantically similar to SQL query queries (which is one of the important reasons why Spark SQL can provide seamless support for DataFrame). The following is an example of a set of user data analysis:In addition to DSL, we can of course, as usual, with SQL to deal with DataFrame:Finally, when the data analysis logic is written, we can save the final result or show it:Behind the scenes: Spark SQL query optimizer with code generationJust as the various transformations of RDD are actually just constructing RDD DAG, various transformations of DataFrame are also lazy. They do not directly calculate the results, but will be assembled into a variety of transformations and RDD DAG similar to the logical query plan. As mentioned earlier, because the DataFrame with schema meta information, Spark SQL query optimizer to insight into the data and the calculation of the fine structure, so the implementation of a highly targeted optimization. Subsequently, the optimized logic execution plan was translated into a physical execution plan and eventually implemented as RDD DAG.The benefits of doing so are reflected in several aspects:1. The user can use fewer declarative code to clarify the calculation logic, the physical execution path is selected by Spark SQL. On the one hand to reduce the development costs, on the one hand also reduces the use of the threshold - in many cases, even if the novice to write a more inefficient query, Spark SQL can also push the conditions of push, column pruning and other strategies to be effectively optimized. This is not available in the RDD API.2. Spark SQL can dynamically generate JVM bytecode for the expression in the physical execution plan, further implement the virtual function call overhead, reduce the number of object allocation and other underlying optimization, so that the final query execution performance can be related to the performance of handwritten code Comparable.3. For PySpark, the use of DataFrame programming only need to build a small logical execution plan, the physical implementation of all by the JVM side responsible for the Python interpreter and JVM between a large number of unnecessary cross-process communication can be removed. As shown in the figure above, a simple set of tests on the aggregation of 10 million integers to PySpark, the performance of the DataFrame API, is nearly five times faster than the RDD API. In addition, PySpark can benefit from Spark SQL's performance improvements to the query optimizer at Scala.External data source API enhancementsFrom the previous text we have seen, Spark 1.3.0 for DataFrame provides a wealth of data source support. One of the highlights is the external data source API introduced by Spark 1.2.0. In 1.3.0, we have further enhanced this API.Data write supportIn Spark 1.2.0, the external data source API can only read data from external data sources into Spark, and can not write the results back to the data source. At the same time, the tables imported and registered through the data source can only be temporary tables, Relevant meta information can not be persisted. In 1.3.0, we provide complete data write support, which complements the last piece of important puzzle for multiple data source interoperability. In the previous example, Hive, Parquet, JSON, Pandas and other data sources between the arbitrary conversion, it is the direct result of this enhancement.At the perspective of Spark SQL external data source developers, the data written to support APIs mainly include:1. Data source table metadata is persistent1.3.0 introduces a new external data source DDL syntax (SQL code snippet)Thus, the SQL tables registered from external data can be either temporary tables or persistent to Hive metastore. In addition to the need to inherit the original RelationProvider, but also need to inherit CreatableRelationProvider.2. InsertableRelationSupport the data to write the external data source of the relation class, need to inherit trait InsertableRelation, and insert method to achieve data insertion logic.The built-in JSON and Parquet data sources in Spark 1.3.0 have implemented the API described above and can serve as a reference example for developing an external data source.Uniform load / save APIIn Spark 1.2.0, in order to preserve the results in SchemaRDD, the choice is not much more convenient. Some of the commonly used include:


- Rdd.saveAsParquetFile (...)
- Rdd.saveAsTextFile (...)
- Rdd.toJSON.saveAsTextFile (...)
- Rdd.saveAsTable (...)
- ...
Can be seen, different data output, the API is not the same. Even more daunting is that we lack a flexible way to extend the new data writing format.
In response to this problem, 1.3.0 unified load / save API, allowing users to freely choose an external data source. This API includes:
1.SQLContext.table
Load the DataFrame from the SQL table.
2.SQLContext.load
Loads the DataFrame from the specified external data source.
3.SQLContext.createExternalTable
Save the data for the specified location as an external SQL table, store the information in Hive metastore, and return the DataFrame containing the corresponding data.
4.DataFrame.save
Writes a DataFrame to the specified external data source.
5.DataFrame.saveAsTable
Save the DataFrame as a SQL table, and the meta information is stored in Hive metastore, and the data is written to the specified location.
Parquet data source enhancement
Spark SQL from the beginning built-in support Parquet this efficient column storage format. After opening the external data source API, the original Parquet support is also gradually turning to external data sources. 1.3.0, the ability of Parquet external data sources has been significantly enhanced. Including schema merge and automatic partition processing.
1.Schema merge
Similar to ProtocolBuffer and Thrift, Parquet also allows users to add new columns over time after defining a schema. As long as they do not modify the meta information of the original column, the new and old schema is still compatible. This feature allows users to add new data columns at any time without having to worry about data migration.
2. Partition information discovery
According to the directory on the same table of data partition storage, Hive and other systems used in a common data storage. The new Parquet data source can automatically discover and deduce partition information based on the directory structure.
3. Partition pruning
Partitioning actually provides a coarse-grained index. When the query conditions only involve part of the partition, through the partition pruning skip the unnecessary scan of the partition directory, you can greatly improve the query performance.
The following Scala code example shows these capabilities (Scala code snippets) for the Parquet data source in 1.3.0:
The result of this code is:
Visible, Parquet data source automatically from the file path found in the key of the partition column, and the correct merger of two different but compatible with the schema. It is worth noting that in the last query query conditions skip the key = 1 this partition. Spark SQL query optimizer will be based on the query conditions will be cut off the partition directory, do not scan the data in the directory, thereby enhancing the query performance.
summary
The introduction of the DataFrame API has changed the RAD API's high-calorie FP posture, making Spark more approachable, making the development experience of large data analysis more and more close to the development experience of traditional standalone data analysis. External data source API is reflected in the inclusive. At present, in addition to the built-in JSON, Parquet, JDBC, the community has emerged in the CSV, Avro, HBase and other data sources, Spark SQL diversified structured data processing capabilities are gradually released.
For developers to provide more expansion points, Spark throughout the 2015 one of the themes. We hope that through these expansion API, effectively detonated the community's energy, so that Spark's ecology is more full and diverse.



Commentaires
Enregistrer un commentaire