Hive: ORC File Format
Written in front of the words , learning Hive so long and found that there is no complete domestic introduction Hive books, and the Internet above the information is messy, so I decided to write some of the "Hive those things" sequence article, shared to everyone.
I will be in the next time finishing the information about Hive, if
interested in Hive things, please pay attention to this blog. Https://www.iteblog.com/archives/tag/hive those things
In Hive, we should have heard of this format RCFile it, on the structure of this file format, I would not have introduced, interested can go online to find. Today's article on the subject is ORC File.
Compared with the RCFile format, ORC File format has the following advantages:
(1), each task only output a single file, this can reduce the NameNode load;
(2), to support a variety of complex data types, such as: datetime, decimal, and some complex types (struct, list, map, and union);
(3), in the file to store some lightweight index data;
(4), based on the data type of block mode compression: a, integer type of column length coding (run-length encoding); b, String type of column dictionary encoding (dictionary encoding);
(5), with a number of independent RecordReaders parallel read the same file;
(6), you can split the file without scanning markers;
(7), binding to read and write the required memory;
(8), the metadata is stored using Protocol Buffers, so it supports adding and removing columns.
By default, the size of a stripe is 250MB. Large size stripes make reading data from HDFS more efficient.
In the file footer which contains the ORC File file stripes information, how many lines per stripe, and the data type of each column. Of course, it also contains some of the column-level aggregation of the results, such as: count, min, max, and sum. The following figure shows the ORC File structure:
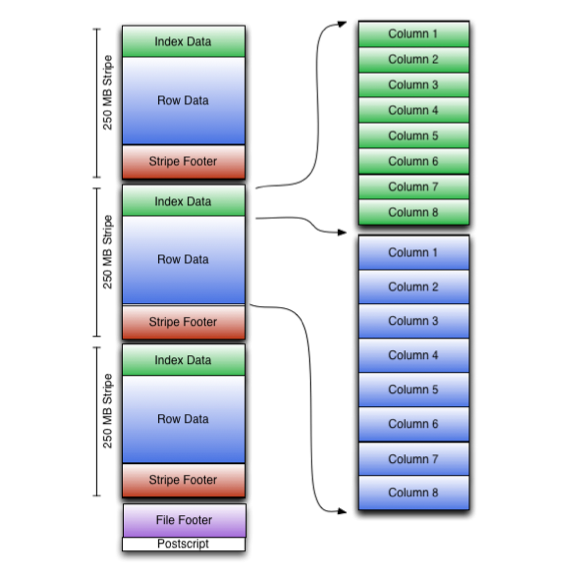
The Index data contains the maximum and minimum values for each column and the rows of each column. The row index provides an offset, which can jump to the correct compressed block position. Has a relatively frequent row index, so that in the stripe in the process of fast reading can skip a lot of lines, although the size of this stripe great. By default, the maximum can be skipped over 10,000 lines. With the ability to skip a large number of rows by filtering predicates, you can sort the secondary keys in the table, which can drastically reduce execution time. For example, if the primary partition of your table is the date of the transaction, you can sort the sub-partitions (state, zip code, and last name).
The following example is to create a table that does not have a compressed ORCFile enabled
Integer Column Serialization
Integer columns are serialized in two streams.
1, present bit stream: is the value non-null?
2, data stream: a stream of integers
Integer data is serialized in a way that takes advantage of the common distribution of numbers:
1, Integers are encoded using a variable-width encoding that has has bytes for small integers.
2, Repeated values are run-length encoded
3, Values that differ by a constant in the range (-128 to 127) are run-length encoded
The variable-width encoding is based on Google's protocol buffers and uses the high bit to represent any this byte is not the last and the lower 7 bits to encode data. To encode negative numbers, a zigzag encoding is used where 0, -1, 1, 2, and 2 map into 0, 1, 2, 3, 4, and 5 respectively.
Each set of numbers is encoded this way:
1, If the first byte (b0) is negative:
-b0 variable-length integers follow.
2, If the first byte (b0) is positive:
It represents b0 + 3 repeated integers
The second byte (-128 to +127) is added between each repetition
1 variable-length integer
In run-length encoding , the first byte specifies run length and whether the values are literals or duplicates. Duplicates can step by -128 to +128. Run-length encoding uses protobuf style variable-length integers.
String Column Serialization
Serialization of string pages uses a dictionary to form unique column values The dictionary is sorted to speed up predications filtering and improve control ratios.
String columns are serialized in four streams.
1, present bit stream: is the value non-null?
2, dictionary data: the bytes for the strings
3, dictionary length: the length of each entry
4, row data: the row values
Both the dictionary length and the row values are run length encoded streams of integers.
In Hive, we should have heard of this format RCFile it, on the structure of this file format, I would not have introduced, interested can go online to find. Today's article on the subject is ORC File.
Article directory
A definition
ORC File, its full name is Optimized Row Columnar (ORC) file, in fact, RCFile has done some optimization. According to the official document, this file format can provide an efficient way to store Hive data. Its design goal is to overcome the Hive other format defects. The use of ORC File can improve Hive's read, write and process data performance.Compared with the RCFile format, ORC File format has the following advantages:
(1), each task only output a single file, this can reduce the NameNode load;
(2), to support a variety of complex data types, such as: datetime, decimal, and some complex types (struct, list, map, and union);
(3), in the file to store some lightweight index data;
(4), based on the data type of block mode compression: a, integer type of column length coding (run-length encoding); b, String type of column dictionary encoding (dictionary encoding);
(5), with a number of independent RecordReaders parallel read the same file;
(6), you can split the file without scanning markers;
(7), binding to read and write the required memory;
(8), the metadata is stored using Protocol Buffers, so it supports adding and removing columns.
Second, ORC File file structure
ORC File contains a set of rows of data, called stripes, in addition, ORC File's file footer also contains some additional auxiliary information. At the end of the ORC File, there is a zone called postscript, which is used to store the size of the compression parameters and the compressed footer.By default, the size of a stripe is 250MB. Large size stripes make reading data from HDFS more efficient.
In the file footer which contains the ORC File file stripes information, how many lines per stripe, and the data type of each column. Of course, it also contains some of the column-level aggregation of the results, such as: count, min, max, and sum. The following figure shows the ORC File structure:
ORC File Format
Third, Stripe structure
From the above figure we can see that each Stripe contains index data, row data and stripe footer. Stripe footer contains the directory of the stream location; Row data is used when the table is scanned.The Index data contains the maximum and minimum values for each column and the rows of each column. The row index provides an offset, which can jump to the correct compressed block position. Has a relatively frequent row index, so that in the stripe in the process of fast reading can skip a lot of lines, although the size of this stripe great. By default, the maximum can be skipped over 10,000 lines. With the ability to skip a large number of rows by filtering predicates, you can sort the secondary keys in the table, which can drastically reduce execution time. For example, if the primary partition of your table is the date of the transaction, you can sort the sub-partitions (state, zip code, and last name).
Four, Hive inside how to use ORCFile
In the construction of the Hive table, we should specify the file storage format. So you can specify in the Hive QL statement with ORCFile this file format, as follows:CREATE TABLE ... STORED AS ORC ALTER TABLE ... [PARTITION partition_spec] SET FILEFORMAT ORC SET hive.default.fileformat=OrcAll of the arguments about ORCFile are in the TBLPROPERTIES field of the Hive QL statement. They are:
| Key | Default | Notes |
|---|---|---|
| Orc.compress | ZLIB | High level compression (one of NONE, ZLIB, SNAPPY) |
| Orc.compress.size | 262,144 | Number of bytes in each compression chunk |
| Orc.stripe.size | 268435456 | Number of bytes in each stripe |
| Orc.row.index.stride | 10,000 | Number of rows between index entries (must be> = 1000) |
| Orc.create.index | True | Whether to create row indexes |
create table Addresses (
name string,
street string,
city string,
state string,
zip int
) stored as orc tblproperties ("orc.compress"="NONE");
Fifth, serialization and compression
Compressing the columns in the ORCFile file is based on the data type of this column is integer or string. What serialization I am not involved in. The Would like to know more about the following English:Integer Column Serialization
Integer columns are serialized in two streams.
1, present bit stream: is the value non-null?
2, data stream: a stream of integers
Integer data is serialized in a way that takes advantage of the common distribution of numbers:
1, Integers are encoded using a variable-width encoding that has has bytes for small integers.
2, Repeated values are run-length encoded
3, Values that differ by a constant in the range (-128 to 127) are run-length encoded
The variable-width encoding is based on Google's protocol buffers and uses the high bit to represent any this byte is not the last and the lower 7 bits to encode data. To encode negative numbers, a zigzag encoding is used where 0, -1, 1, 2, and 2 map into 0, 1, 2, 3, 4, and 5 respectively.
Each set of numbers is encoded this way:
1, If the first byte (b0) is negative:
-b0 variable-length integers follow.
2, If the first byte (b0) is positive:
It represents b0 + 3 repeated integers
The second byte (-128 to +127) is added between each repetition
1 variable-length integer
In run-length encoding , the first byte specifies run length and whether the values are literals or duplicates. Duplicates can step by -128 to +128. Run-length encoding uses protobuf style variable-length integers.
String Column Serialization
Serialization of string pages uses a dictionary to form unique column values The dictionary is sorted to speed up predications filtering and improve control ratios.
String columns are serialized in four streams.
1, present bit stream: is the value non-null?
2, dictionary data: the bytes for the strings
3, dictionary length: the length of each entry
4, row data: the row values
Both the dictionary length and the row values are run length encoded streams of integers.



Commentaires
Enregistrer un commentaire