Spark SQL Catalyst source code analysis of the UDF (6)
In
the world of SQL, in addition to the official use of the commonly used
processing functions, generally provide a scalable external custom
function interface, which has become a de facto standard.
In the previous Spark SQL source code analysis of the core process, has introduced the role of Spark SQL Catalyst Analyzer, which contains ResolveFunctions this resolution function. But with the Spark1.1 version of the release, Spark SQL code has a lot of new and new features, and I earlier based on the 1.0 source code analysis somewhat different, such as support for UDF:
Spark1.0 and previous implementations:
Copy the code
Spark1.1 and later implementations:
Copy the code
First, the primer:
For the SQL statement in the function, will be resolved by SqlParser UnresolvedFunction. UnresolvedFunction is finally parsed by Analyzer.
SqlParser:
In addition to the unofficial definition of the function, you can also define a custom function, sql parser will be resolved.
Copy the code
The SqlParser passed udfName and exprs are encapsulated into a class class UnresolvedFunction inherited from Expression.
Only this expression of dataType and a series of properties and eval calculation methods are unable to access, forced access will throw an exception, because it is not Resolved, just a carrier.
Copy the code
Analyzer:
Analyzer initialization will need Catalog, database and table metadata relationship, and FunctionRegistry to maintain UDF name and UDF implementation of the metadata, where the use of SimpleFunctionRegistry.
Copy the code
Second, UDF registration
2.1 UDFRegistration

RegisterFunction ("len", (x: String) => x.length)
RegisterFunction is a UDFRegistration method, SQLContext now implements the UDFRegistration this trait, as long as the import SQLContext, you can use udf function.
UDFRegistration core method registerFunction:
RegisterFunction method signature def registerFunction [T: TypeTag] (name: String, func: Function1 [_, T]): Unit
Accept a udfName and a FunctionN, which can be Function1 to Function22. That the parameters of this udf only support 1-22. (Scala's pain)
The internal builder constructs an Expression through ScalaUdf, where ScalaUdf inherits from Expression (which simply understands the current SimpleUDF is an expression of a Catalyst), passes the scala function as a UDF implementation, and checks whether the field type is a reflection Allow, see ScalaReflection.
Copy the code
2.2 Register Function:
Note: Here FunctionBuilder is a type FunctionBuilder = Seq [Expression] => Expression
Copy the code
At this point, we will be a scala function registered as a catalyst of an Expression, which is spark simple udf.
Third, UDF calculation:
UDF has been encapsulated as an Expression node in the catalyst tree, then the calculation is calculated when the ScalaUdf eval method.
First through the Row and expression calculation function required parameters, and finally through the call function call to achieve the purpose of calculating udf.
ScalaUdf inherited from Expression:
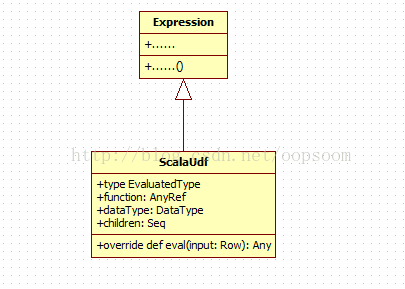
ScalaUdf accepts a function, dataType, and a series of expressions.
Relatively simple to see the note can be:
Copy the code
Four, summary
Spark's current UDF is actually scala function. Encapsulate scala function into a Catalyst Expression, and use the same Eval method to calculate the current input Row when doing sql calculations.
Writing a spark udf is very simple, just give the UDF a function name, and pass a scala function. Relying on scala function programming performance, making the preparation of scala udf relatively simple, and compared to hive udf easier to understand.
In the previous Spark SQL source code analysis of the core process, has introduced the role of Spark SQL Catalyst Analyzer, which contains ResolveFunctions this resolution function. But with the Spark1.1 version of the release, Spark SQL code has a lot of new and new features, and I earlier based on the 1.0 source code analysis somewhat different, such as support for UDF:
Spark1.0 and previous implementations:
- Protected [sql] lazy val catalog: Catalog = new SimpleCatalog
- @transient
- Protected [sql] lazy val analyzer: Analyzer =
- New Analyzer (catalog, EmptyFunctionRegistry, caseSensitive = true) // EmptyFunctionRegistry
- @transient
- Protected [sql] val optimizer = Optimizer
Spark1.1 and later implementations:
- Protected [sql] lazy val functionRegistry: FunctionRegistry = new SimpleFunctionRegistry // SimpleFunctionRegistry implementation, support for simple UDF
- @transient
- Protected [sql] lazy val analyzer: Analyzer =
- New Analyzer (catalog, functionRegistry, caseSensitive = true)
First, the primer:
For the SQL statement in the function, will be resolved by SqlParser UnresolvedFunction. UnresolvedFunction is finally parsed by Analyzer.
SqlParser:
In addition to the unofficial definition of the function, you can also define a custom function, sql parser will be resolved.
- Ident ~ "(" ~ repsep (expression, ",") <~ ")" ^^ {
- Case udfName ~ _ ~ exprs => UnresolvedFunction (udfName, exprs)
The SqlParser passed udfName and exprs are encapsulated into a class class UnresolvedFunction inherited from Expression.
Only this expression of dataType and a series of properties and eval calculation methods are unable to access, forced access will throw an exception, because it is not Resolved, just a carrier.
- Case class UnresolvedFunction (name: String, children: Seq [Expression]) extends Expression {
- Override def dataType = throw new UnresolvedException (this, "dataType")
- Override def foldable = throw new UnresolvedException (this, "foldable")
- Override def nullable = throw new UnresolvedException (this, "nullable")
- Override lazy val resolved = false
- // Unresolved functions are transient at compile time and do not get published
- Override def eval (input: Row = null): EvaluatedType =
- Throw new TreeNodeException (this, s "No function to evaluate expression. Type: $ {this.nodeName}")
- Override def toString = s "'$ name ($ {children.mkString (", ")})"
- } <Strong> </ strong>
Analyzer:
Analyzer initialization will need Catalog, database and table metadata relationship, and FunctionRegistry to maintain UDF name and UDF implementation of the metadata, where the use of SimpleFunctionRegistry.
- / **
- * Replaces [[UnresolvedFunction]] s with concrete [[catalyst.expressions.Expression Expressions]].
- * /
- Object ResolveFunctions extends Rule [LogicalPlan] {
- Def apply (plan: LogicalPlan): LogicalPlan = plan transform {
- Case q: LogicalPlan =>
- Q transformExpressions {// transforms the current LogicalPlan
- Case u @ UnresolvedFunction (name, children) if u.childrenResolved => // If traversal to UnresolvedFunction
- Registry.lookupFunction (name, children) // Find the udf function from the UDF metadata table
- }
- }
- }
Second, UDF registration
2.1 UDFRegistration
RegisterFunction ("len", (x: String) => x.length)
RegisterFunction is a UDFRegistration method, SQLContext now implements the UDFRegistration this trait, as long as the import SQLContext, you can use udf function.
UDFRegistration core method registerFunction:
RegisterFunction method signature def registerFunction [T: TypeTag] (name: String, func: Function1 [_, T]): Unit
Accept a udfName and a FunctionN, which can be Function1 to Function22. That the parameters of this udf only support 1-22. (Scala's pain)
The internal builder constructs an Expression through ScalaUdf, where ScalaUdf inherits from Expression (which simply understands the current SimpleUDF is an expression of a Catalyst), passes the scala function as a UDF implementation, and checks whether the field type is a reflection Allow, see ScalaReflection.
- Def registerFunction [T: TypeTag] (name: String, func: Function1 [_, T]): Unit = {
- Def builder (e: Seq [Expression]) = ScalaUdf (func, ScalaReflection.schemaFor (typeTag [T]). DataType, e) // Constructs Expression
- FunctionRegistry.registerFunction (name, builder) // to functionRegistry of SQLContext (which maintains a hashMap to manage udf mappings)
2.2 Register Function:
Note: Here FunctionBuilder is a type FunctionBuilder = Seq [Expression] => Expression
- Class SimpleFunctionRegistry extends FunctionRegistry {
- Val functionBuilders = new mutable.HashMap [String, FunctionBuilder] () // udf mapping relationship maintenance [udfName, Expression]
- Def registerFunction (name: String, builder: FunctionBuilder) = {// put expression into Map
- FunctionBuilders.put (name, builder)
- }
- Override def lookupFunction (name: String, children: Seq [Expression]): Expression = {
- FunctionBuilders (name) (children) // Find udf and return to Expression
- }
- }
At this point, we will be a scala function registered as a catalyst of an Expression, which is spark simple udf.
Third, UDF calculation:
UDF has been encapsulated as an Expression node in the catalyst tree, then the calculation is calculated when the ScalaUdf eval method.
First through the Row and expression calculation function required parameters, and finally through the call function call to achieve the purpose of calculating udf.
ScalaUdf inherited from Expression:
ScalaUdf accepts a function, dataType, and a series of expressions.
Relatively simple to see the note can be:
- Case class ScalaUdf (function: AnyRef, dataType: DataType, children: Seq [Expression])
- Extends Expression {
- Type EvaluatedType = Any
- Def nullable = true
- Override def toString = s "scalaUDF ($ {children.mkString (", ")})"
- Override def eval (input: Row): Any = {
- Val result = children.size match {
- Case 0 => function.asInstanceOf [() => Any] ()
- Case 1 => function.asInstanceOf [(Any) => Any] (children (0) .eval (input)) // Reflection call function
- Case 2 =>
- Function.asInstanceOf [(Any, Any) => Any] (
- Children (0) .eval (input), // expression parameter calculation
- Children (1) .eval (input))
- Case 3 =>
- Function.asInstanceOf [(Any, Any, Any) => Any] (
- Children (0) .eval (input),
- Children (1) .eval (input),
- Children (2) .eval (input)
- Case 4 =>
- ...
- Case 22 => // scala function only supports 22 parameters, here enumerated.
- () Any (Any, Any, Any, Any, Any, Any, Any, Any, Any, Any, Any, Any, Any, Any, Any, Any, Any, Any, Any, Any) = > Any] (
- Children (0) .eval (input),
- Children (1) .eval (input),
- Children (2) .eval (input),
- Children (3) .eval (input),
- Children (4) .eval (input),
- Children (5) .eval (input),
- Children (6) .eval (input),
- Children (7) .eval (input),
- Children (8) .eval (input),
- Children (9) .eval (input),
- Children (10) .eval (input),
- Children (11) .eval (input),
- Children (12) .eval (input),
- Children (13) .eval (input),
- Children (14) .eval (input),
- Children (15) .eval (input),
- Children (16) .eval (input),
- Children (17) .eval (input),
- Children (18) .eval (input),
- Children (19) .eval (input),
- Children (20) .eval (input),
- Children (21) .eval (input)
Four, summary
Spark's current UDF is actually scala function. Encapsulate scala function into a Catalyst Expression, and use the same Eval method to calculate the current input Row when doing sql calculations.
Writing a spark udf is very simple, just give the UDF a function name, and pass a scala function. Relying on scala function programming performance, making the preparation of scala udf relatively simple, and compared to hive udf easier to understand.



Commentaires
Enregistrer un commentaire