Use mongodb in spark
Suitable for readers
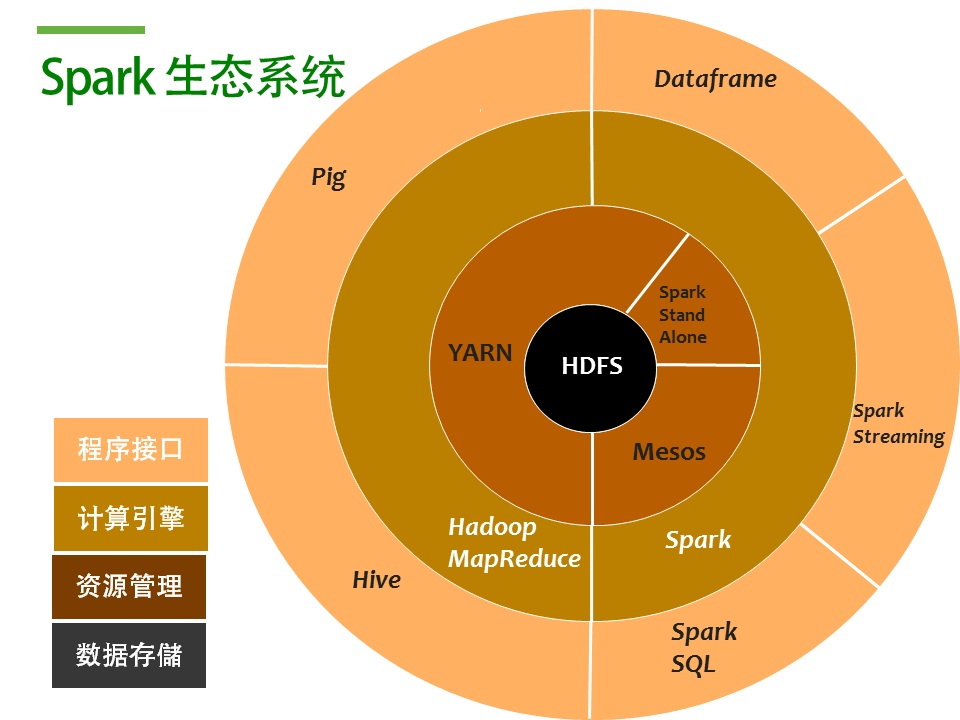
Traditional Spark ecosystem and MongoDB's role in Spark Ecology
Replace the Spark ecosystem with HDFS after using MongoDB

Why use MongoDB to replace HDFS
MongoDB Spark Connector Introduction
MongoDB Spark sample code
Sample code
to sum up
- Being using Mongodb developers
Traditional Spark ecosystem and MongoDB's role in Spark Ecology
Traditional Spark ecosystem
Then Mongodb as a database, what role can be held? This is the data
store this part, that is, the black circle in the figure HDFS part, as
shown below
Replace the Spark ecosystem with HDFS after using MongoDB
Why use MongoDB to replace HDFS
- Storage mode, HDFS to file as a unit, each file 64MB ~ 128MB range, and MongoDB as a document database is more granular performance
- MongoDB supports the concept of indexing that HDFS does not have, so it's faster on reading
- MongoDB support the addition and deletion of features than HDFS easier to modify the written data
- HDFS has a response level of minutes, and MongoDB is usually a millisecond level
- If the existing database is already MongoDB, then there is no need to dump a copy of the HDFS
- Can use MongoDB powerful Aggregate to do data filtering or preprocessing
MongoDB Spark Connector Introduction
- Support read and write, that can be calculated after the results written to MongoDB
- The query will be split into n sub-tasks, such as the Connector will be a match, split into a number of sub-tasks to the spark to deal with, reduce the full amount of data read
MongoDB Spark sample code
Calculate the number of message characters of type Type = 1 and group them by userid
Develop Maven dependency configuration
Here is the use of mongo-spark-connector_2.11 version 2.0.0 and spark spark-core_2.11 version 2.0.2
[XML] plain text view copy code
<Dependency> <GroupId> org.mongodb.spark </ groupId> <ArtifactId> mongo-spark-connector_2.11 </ artifactId> <Version> 2.0.0 </ version> </ Dependency> <Dependency> <GroupId> org.apache.spark </ groupId> <ArtifactId> spark-core_2.11 </ artifactId> <Version> 2.0.2 </ version> </ Dependency>
Sample code
[Scala] plain text view copy code
Import com.mongodb.spark._ Import org.apache.spark. {SparkConf, SparkContext} Import org.bson._ Val conf = new SparkConf () .setMaster ("local") .setAppName ("Mingdao-Score") // also supports the mongo-driven readPreference configuration, which can only read data from secondary .set ("spark.mongodb.input.uri", "mongodb: //xxx.xxx.xxx.xxx: 27017, xxx.xxx. Xxx: 27017, xxx.xxx.xxx: 27017 / inputDB.collectionName ") .set ("spark.mongodb.output.uri", "mongodb: //xxx.xxx.xxx.xxx: 27017, xxx.xxx.xxx: 27017, xxx.xxx.xxx: 27017 / outputDB.collectionName") Val sc = new SparkContext (conf) // create rdd Val originRDD = MongoSpark.load (sc) // construct query val dateQuery = new BsonDocument () .append ("$ gte", new BsonDateTime (start.getTime)) .append ("$ lt", new BsonDateTime (end.getTime)) Val matchQuery = new Document ("$ match", BsonDocument.parse ("{\" type \ ": \" 1 \ "}")) // construct Projection Val projection1 = new BsonDocument ("$ project", BsonDocument.parse ("{\" userid \ ": \" $ userid \ ", \" message \ ": \" $ message \ "}") Val aggregatedRDD = originRDD.withPipeline (Seq (matchQuery, projection1)) // Calculate the number of message characters for the user val rdd1 = aggregatedRDD.keyBy (x => { Map ( "Userid" -> x.get ("userid") ) }) Val rdd2 = rdd1.groupByKey.map (t => { (T._1, t._2.map (x => { X.getString ("message"). Length }). Sum) }) Rdd2.collect (). Foreach (x => { Println (x) }) // keep the statistics to MongoDB outputurl specified by the database MongoSpark.save (rdd2)
to sum up
Reference linkMongoDB Connector document only the basic example of the code, the specific details need to see GitHub example and part of the source code



Commentaires
Enregistrer un commentaire