Organize the understanding of Spark SQL
Question guide
1, what features does Spark support?
2, Spark and Hadoop contrast is what?
3, how to understand Spark's logic implementation plan?

Catalyst
Catalyst is an independent library decoupled with Spark and is an impl-free implementation plan for the generation and optimization of the framework.
Currently coupled with the Spark Core, this user mail group was questioned, see mail.
The following is the architecture of Catalyst earlier, showing the code structure and processing flow.
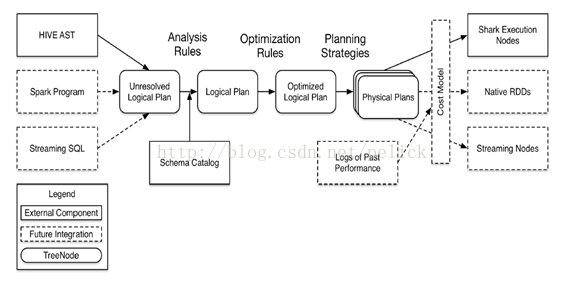
Catalyst positioning <br /> Other systems If you want to do some classes based on Spark sql, standard sql or even other query language query, based on the Catalyst provided by the parser, the implementation of the planning tree structure, the logic of the implementation of the scheduling system rules and other systems To achieve the implementation of the plan analysis, generation, optimization, mapping work.
Corresponding to the above figure, mainly on the left side of the TreeNodelib and the middle of the transformation process involved in the class structure are provided by Catalyst. As for the right physical execution plan mapping generation process, the physical execution plan is based on the cost optimization model, the implementation of specific physical operators by the system itself.
Catalyst present <br /> in the parser is provided by a simple scala written sql parser, support semantics is limited, and should be the standard sql.
In terms of rules, the optimization rules provided are relatively basic (and Pig / Hive is not so rich), but some optimization rules are actually related to the specific physical operator, so some of the rules need to be developed and implemented in the system side (Such as SparkStrategy in spark-sql).
Catalyst also has its own set of data types.
Here are a few sets of important Catalyst class structure.
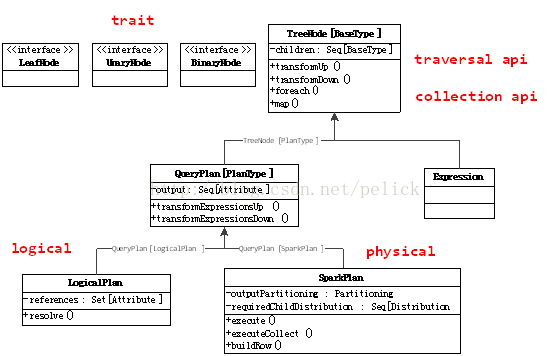
TreeNode system
TreeNode is the data structure represented by the Catalyst execution plan, is a tree structure with some scala collection operation capability and tree traversal capability. The tree is maintained in memory and will not be dumped to disk in a formatted file, and the tree is modified to replace the existing node, either during the logical execution plan or the optimized logic execution plan. The
TreeNode, with a children inside: Seq [BaseType] that child nodes, with foreach, map, collect and other methods for node operations, as well as transformDown (default, preorder traversal), transformUp such a traversal tree node, the implementation of matching nodes Change the method.
Provide UnaryNode, BinaryNode, LeafNode three trait, that is, non-leaf nodes allow one or two sub-nodes.
TreeNode provides a paradigm.
TreeNode has two subclass inheritance systems, QueryPlan and Expression. QueryPlan The following is a logical and physical execution plan two systems, the former in the Catalyst in a detailed realization, which needs to be implemented in the system itself. Expression is the expression system, the following chapters will be introduced.
Tree's transformation implementation:
Passed PartialFunction [TreeType, TreeType], if the match with the operator, the node will be replaced by the results, otherwise the node will not change. The whole process is recursively performed on children.
Execute the plan to represent the model
Logical execution plan
QueryPlan inherited from TreeNode, with an internal output: Seq [Attribute], with transformExpressionDown, transformExpressionUp method.
In Catalyst, the main subclass of QueryPlan is LogicalPlan, the logical execution plan representation. The physical execution plan is represented by the consumer (spark-sql project).
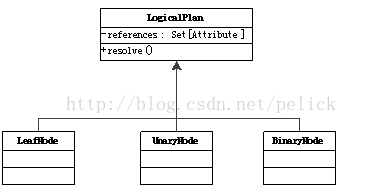
LogicalPlan inherits from QueryPlan with a reference: Set [Attribute], the main method is resolve (name: String): Option [NamedeExpression], used to analyze the corresponding NamedExpression.
LogicalPlan has many specific subclasses, also divided into UnaryNode, BinaryNode, LeafNode three categories, specifically in the org.apache.spark.sql.catalyst.plans.logical path.
Logical implementation plan implementation
LeafNode main subclass is Command system:
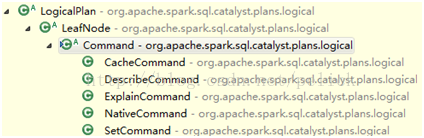
The semantics of each command can be seen from the subclass name, representing the non-query command that the system can execute, such as DDL.
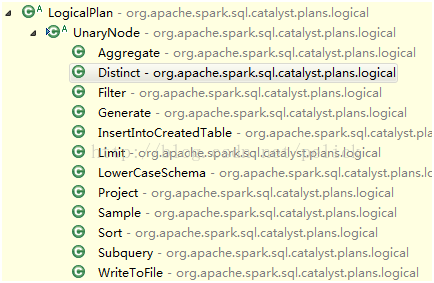
Subclass of UnaryNode:
Subclass of BinaryNode:

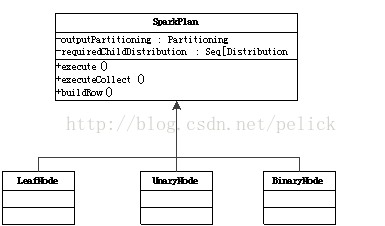
Physical Execution Plan <br /> On the other hand, the physical execution plan node is implemented in a specific system, such as the SparkPlan inheritance system in the spark-sql project.
The physical execution plan implementation of each subclass to achieve execute () method, generally have the following subclass implementation (incomplete).
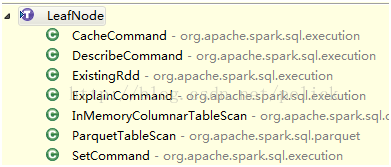
Subclass of LeadNode:
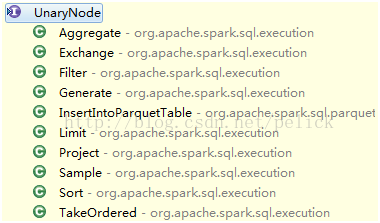
Subclass of UnaryNode:
Subclass of BinaryNode:
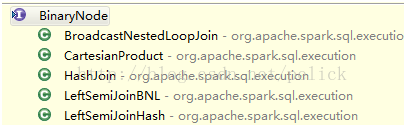
Refer to the physical execution plan and mention the partition representation model provided by Catalyst.
Perform a plan mapping
Catalyst also provides a QueryPlanner [Physical <: TreeNode [PhysicalPlan]] abstract class, the need for subclasses to develop a number of strategies: Seq [Strategy], the apply method is similar to the specific strategy developed according to the logic of the implementation of the plan operator mapping Physical execution plan operator. As the physical execution plan node is implemented in a specific system, so QueryPlanner and the inside of the strategy also need to be implemented in a specific system.
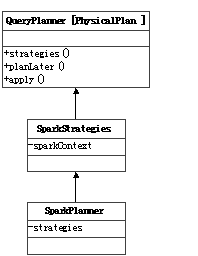
In the spark-sql project, SparkStrategies inherited QueryPlanner [SparkPlan], the internal development of the LeftSemiJoin, HashJoin, PartialAggregation, BroadcastNestedLoopJoin, CartesianProduct and several other strategies, each strategy is a LogicalPlan, generated Seq [SparkPlan] Each SparkPlan is understood as a specific RDD operator.
For example, in BasicOperators this Strategy, in a match-case match the way to deal with a lot of basic operators (one can directly mapped to RDD operator), as follows:
Copy the code
Expression system
Expression, that is, expression, that does not need to perform the engine calculation, and can directly calculate or deal with the node, including the Cast operation, Projection operation, four operations, logic operator operations.
You can refer to the class under org.apache.spark.sql.expressionspackage.
Rules System <br /> RulesExecutor [TreeType] abstract classes are required to inherit the execution plan tree (Analyze process, Optimize process, SparkStrategy process), implement rule matching and node processing.
RuleExecutor internally provides a Seq [Batch], which is defined by the RuleExecutor processing steps. Each Batch represents a set of rules that are equipped with a policy that describes the number of iterations (one or more times).
Copy the code
Rule [TreeType <: TreeNode [_]] is an abstract class that subclasses need to override the apply (plan: TreeType) method to formulate the processing logic.
RuleExecutor apply (plan: TreeType): The TreeType method will iterate over the nodes in the incoming plan according to the batches order and the Rules order in the batch. The processing logic is implemented by the concrete Rule subclass.
Hive related
Hive support
Spark SQL support for hive is a separate spark-hive project, support for Hive includes HQL query, hive metaStore information, hive SerDes, hive UDFs / UDAFs / UDTFs, similar to Shark.
Only in the HiveContext under the hive api obtained from the data set, you can use hql query, the analysis of its hql is dependent on the org.apache.hadoop.hive.ql.parse.ParseDriver class parse method to generate Hive AST.
In fact sql and hql, not with the support. Can be understood as hql is independent support, can be hql query data set must be read from the hive api. The following figure in the parquet, json and other file support only occurred in the sql environment (SQLContext).

Hive on Spark
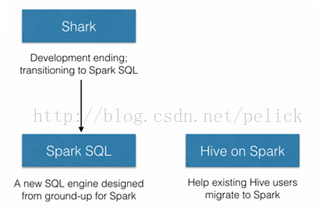
Hive official made Hive onSpark's JIRA. Shark after the end, split into two directions:
Spark SQL is now on the Hive support, reflected in the reuse of the Hive meta store data, hql parsing, UDFs, SerDes, in the implementation of DDL and some simple commands, the tune is hive client. Hql translation will deal with some of the query principal has nothing to do with the set, cache, addfile and other commands, and then call ParserDriver translation hql, and AST into Catalyst LogicalPlan, follow-up optimization, physical execution plan translation and implementation process, and Sql used the same Is the content provided by Catalyst, the implementation engine is Spark. Throughout the binding process, ASTNode is mapped to LogicalPlan as the focus.

And Hive community Hive on Spark will be how to achieve, the specific reference jira in the design documents.
Contrast with Shark,
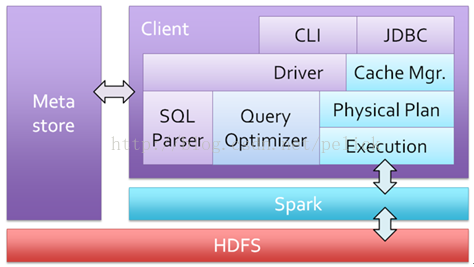
Shark relies heavily on Hive's execution plan related modules and CLI. The CLI and JDBC sections are supported by Spark SQL follow-up. Shark additional provision of the Table data row column, serialization, compression memory module, also received the Spark Sql sql project.
The above describes the difference between Shark and Spark SQL Hive, Shark inheritance of this project understanding.
The Spark SQL Hive and Hive community Hive on Spark the need for a specific reference jira in the design of the document, I have not read.
Spark-hive works

Analysis process
HiveQl.parseSql () Hql resolved into logicalPlan. Parse the process, extract some commands, including:
2 set key = value
2 cache table
2 uncache table
2 add jar
2 add file
2 dfs
2 source
And then by Hive's ParseDriver Hql resolved into AST, get ASTNode,
Copy the code
The Node into the Catalyst LogicalPlan, conversion logic is more complex, but also Sparksql support the most critical part of hql. See HiveQl.nodeToPlan (node: Node) for details: LogicalPlan method.
The approximate conversion logic includes:
Handle TOK_EXPLAIN and TOK_DESCTABLE
Handle TOK_CREATETABLE, including the set of tables to create a set of table set TOK_XXX
Handle TOK_QUERY, including TOK_SELECT, TOK_WHERE, TOK_GROUPBY, TOK_HAVING, TOK_SORTEDBY, TOK_LIMIT, etc., and nodeToRelation of the statement followed by FROM.
Handle TOK_UNION
Hive AST tree structure and that are not familiar, so here omitted.
Analyze the process
Metadata interaction
Catalog class for the HiveMetastoreCatalog, through the hive conf generated client (org.apache.hadoop.hive.ql.metadata.Hive, used to communicate with MetaStore, access to metadata and DDL operation), catalog lookupRelation method inside, client.getTable ( Get the table information, client.getAddPartitionsForPruner () get the partition information.
Udf related
FunctionRegistry class HiveFunctionRegistry, according to the method name, through the hive related class to query the method, check whether the method is UDF, or UDAF (aggregation), or UDTF (table). Here only udf inquiries, do not do the new method include.
The inheritance relationship with Catalyst's Expression is as follows:
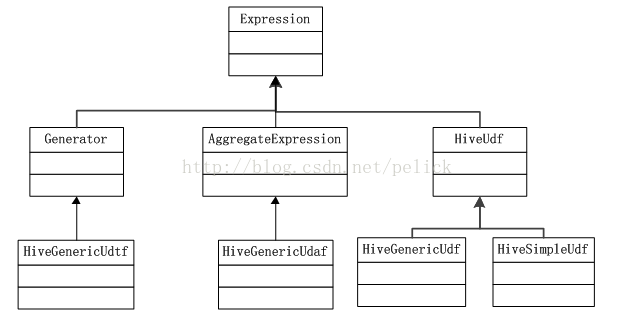
Inspector related
HiveInspectors provides several methods for mapping data types and ObjectInspetor subclasses, including PrimitiveObjectInspector, ListObjectInspector, MapObjectInspector, and StructObjectInspector
Optimizer process <br /> before making the optimization , will try to generate a logical execution plan for the createtabl operation, because the implementation of the hql may be "CREATE TABLE XXX", this part of the processing HiveMetastoreCatalog CreateTables single case, inherited the Rule [LogicalPlan].
And PreInsertionCasts processing, but also HiveMetastoreCatalog in a single case, inherited the Rule [LogicalPlan].
After the optimizer process with the SQLContext, with the same Catalyst provided Optimizer class.
Planner and the implementation process
HiveContext inherits from SQLContext, and its QueryExecution also inherits from QueryExecution from SQLContext. Subsequent execution plan optimization, physical execution plan translation, processing and implementation process is consistent with the SQL processing logic.
Translation of the physical implementation plan, hive planner developed a specific strategy, and SparkPlanner slightly different.
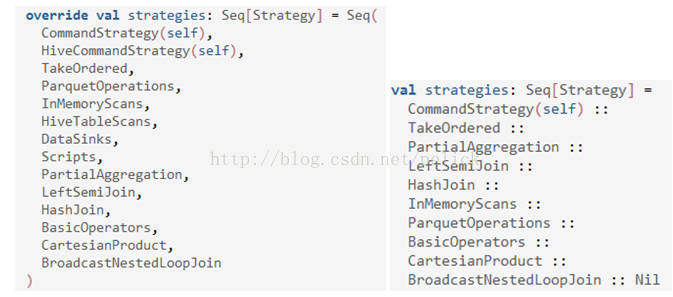
More Scripts, DataSinks, HiveTableScans, and HiveCommandStrategy have four strategies for handling physical execution plans (see HiveStrategies).
1. Scripts, used to deal with the kind of hive command line execution script. Implementation is the use of ProcessBuilder new JVM process from the way, "/ bin / bash-c scripts" way to execute the script and get the output stream data, into the Catalyst Row data format.
2. DataSinks, used to write data to the case of the Hive table. Which involves some hive read and write data format conversion, serialization, read configuration and so on, and finally through the SparkContext runJob interface, submit the job.
3. HiveTableScans, used to scan the hive table, support the use of predicate partition clipping (Partition pruning predicates are detected and applied).
4. HiveCommandStrategy, used to execute native command and describe command. I understand that this order is directly transferred hive client stand-alone implementation, because it may only deal with meta data.
ToRDD: RDD [Row] processing is also a little different, return RDD [Row], when each element made a copy.
SQL Core
Spark SQL is the core of the existing RDD, with Schema information, and then registered as sql Lane "Table", its sql query. This is mainly divided into two parts, one is generated SchemaRD, the second is the implementation of the query.
Generate SchemaRDD
If it is spark-hive project, then read the metadata information as a Schema, read the process of data on the hdfs to Hive completed, and then according to the two parts generated SchemaRDD, HiveContext under the hql () query.
For Spark SQL,
In terms of data, RDD can come from any existing RDD, or from supported third-party formats such as json file, parquet file.
SQLContext will implicitly convert RDD with case class into SchemaRDD
Copy the code
ExsitingRdd will reflect the case class attributes, and the RDD data into Catalyst's GenericRow, and finally return RDD [Row], that is, a SchemaRDD. Here the specific transformation logic can refer to ExsitingRdd's productToRowRdd and convertToCatalyst methods.
After the SchemaRDD can be provided by the registration table operation, for the Schema replication part of the RDD conversion operations, DSL operations, saveAs operations and so on.
Row and GenericRow are the row representation models in Catalyst
Row uses Seq [Any] to represent values, GenericRow is a subclass of Row, representing values with an array. Row supports data types including Int, Long, Double, Float, Boolean, Short, Byte, String. Supports reading the value of a column in ordinal. Before reading the need to do isNullAt (i: Int) to judge.
Each has a Mutable class that provides setXXX (i: int, value: Any) to modify the value on an ordinal.
Hierarchy

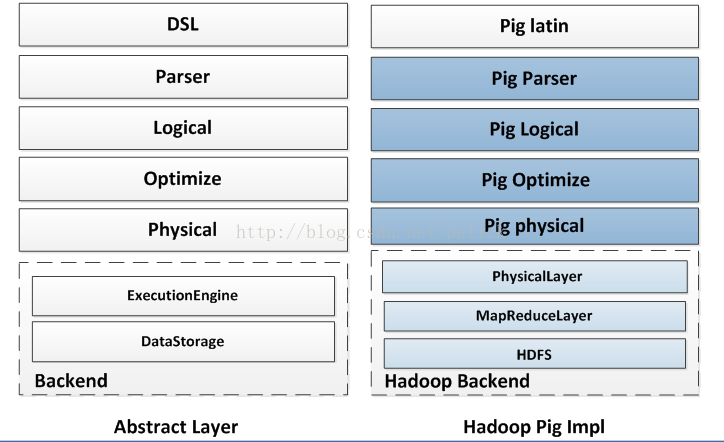
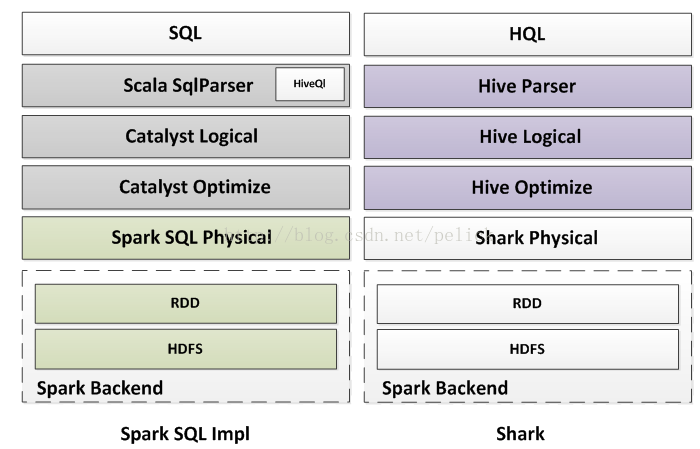
The following figure roughly compares Pig, Spark SQL, Shark in the realization of the level of the difference, only for reference.
Query flow
SQLContext Lane on the analysis of sql and the implementation of the process:
1. The first step parseSql (sql: String), simple sql parser grammar parsing, generate LogicalPlan.
2. The second step analyzer (logicalPlan), to complete the lexical syntax analysis of the implementation of the initial analysis and mapping,
The current Analyzer in SQLContext is provided by Catalyst and is defined as follows:
New Analyzer (catalog, EmptyFunctionRegistry, caseSensitive = true)
Catalog for SimpleCatalog, catalog is used to register table and query relation.
And here the FunctionRegistry does not support the lookupFunction method, so the analyzer does not support Function registration, that is, UDF.
Several rules are defined in Analyzer:
Copy the code
3. From the second step is the initial logicalPlan, followed by the third step is optimizer (plan).
Optimizer which also defines a number of rules, will be in order to optimize the implementation of the plan.
Copy the code
4. Optimized execution plan, but also to the SparkPlanner processing, which defines a number of strategies, the purpose is based on the logical implementation of the tree to generate the final implementation of the physical execution plan tree, that is, SparkPlan.
Copy the code
5. In the final implementation of the actual implementation of the physical plan, and finally to the two rules, SQLContext definition of this process is called prepareExExution, this step is an additional increase, directly new RuleExecutor [SparkPlan] carried out.
Copy the code
6. Finally call SparkPlan execute () to perform the calculation. This execute () is defined in the implementation of each SparkPlan, which normally recursively calls children's execute () method, so it triggers the calculation of the whole tree.
Other features
Memory column storage
SQLContext cache / uncache table will be called when the column storage module.
The module from the Shark, the purpose is to table data cache in the memory when the line to do the operation, in order to compress.
Implementation class
The InMemoryColumnarTableScan class is an implementation of the SparkPlan LeafNode, which is a physical execution plan. Pass a SparkPlan (a confirmed physical execution) and a sequence of attributes that contain a row of rows that trigger the process of calculating and caching (and lazy).
ColumnBuilder writes data to ByteBuffer from different subclasses for different data types (boolean, byte, double, float, int, long, short, string). Corresponding to the ColumnAccessor is to access the column, turn it back to Row.
CompressibleColumnBuilder and CompressibleColumnAccessor is a compressed row and column converter builder whose ByteBuffer internal storage structure is as follows
[Java] view plaincopy View the code slice on CODE to my code slice
* .--------------------------- Column type ID (4 bytes)
* | .----------------------- Null count N (4 bytes)
* | | .------------------- Null positions (4 x N bytes, empty if null count is zero)
* | | | .------------- Compression scheme ID (4 bytes)
* | | | | .- Compressed non-null elements
* V V V V V
* + --- + --- + ----- + --- + --------- +
* | | | ... | | ... ...
* + --- + --- + ----- + --- + --------- +
* \ ----------- / \ ----------- /
* Header body
The CompressionScheme subclass is a different compression implementation
Are scala implementation, not with third-party library. Different implementations specify the supported column data type. In the build (), will compare each compression, select the minimum compression rate (if still greater than 0.8 is not compressed).
Here the estimation logic, from the subclass implementation of the gatherCompressibilityStats method.
Cache logic
Cache, you need to first of this cache table of the physical implementation plan generated.
In the cache process, InMemoryColumnarTableScan did not trigger the implementation, but generated in the InMemoryColumnarTableScan for the physical implementation of the plan SparkLogicalPlan, and the table into the plan.
In fact, when the cache, the first to catalog to find the table of information and table implementation of the plan, and then will be implemented (the implementation of the implementation of the physical implementation plan), and then put the table back to the catalog to maintain up, this time the implementation of The plan is already the final implementation of the physical execution plan. But at this time Columner module-related conversion and other operations are not triggered.
The real trigger is still in the execute () time, with the other SparkPlan execute () method to trigger the scene is the same.
Uncache logic
UncacheTable, in addition to delete the table table information, but also called InMemoryColumnarTableScan the cacheColumnBuffers method, get RDD collection, and unpersist () operation. CacheColumnBuffers mainly to the RDD each partition in the ROW of each Field to the ColumnBuilder.
UDF (not supported)
As in the previous analysis of SQLContext Lane Analyzer, the FunctionRegistry did not implement the lookupFunction.
In the spark-hive project, HiveContext Lane is to achieve the FunctionRegistry the trait, which is implemented as HiveFunctionRegistry, the realization of logic see org.apache.spark.sql.hive.hiveUdfs
Parquet supports <br /> to be collated
Http://parquet.io/
Specific Docs and Codes:
Https://github.com/apache/incubator-parquet-format
Https://github.com/apache/incubator-parquet-mr
Http://www.slideshare.net/julienledem/parquet-hadoop-summit-2013
JSON support
SQLContext, the increase jsonFile read method, and now look at the code to achieve isoop textfile read, that is, the json file should be on the HDFS. Specific json file loading, InputFormat is TextInputFormat, key class is LongWritable, value class is Text, and finally get the value of that part of the String content, that is, RDD [String].
In addition to jsonFile, also supports jsonRDD, example:
Http://spark.apache.org/docs/lat ... .html # json-datasets
After reading the json file, convert it to SchemaRDD. JsonRDD.inferSchema (RDD [String]) in a detailed analysis of the json and mapping out the schema process, and finally get the json LogicalPlan.
Json's parsing uses the FasterXML / jackson-databind library, the GitHub address , the wiki
Map the data into Map [String, Any]
Json's support enriches Spark SQL data access scenarios.
JDBC support
Jdbc support branchis under going
SQL92
Spark SQL The current SQL syntax support is available in the SqlParser class. The goal is to support SQL92? The
1. Basic applications, sql server and oracle are followed sql 92 grammar standards .
2. Practical applications, we will exceed the above criteria, the use of various database vendors have provided a wealth of custom standard library and syntax.
3. Microsoft sql server sql extension called T-SQL (Transcate SQL).
4. Oracle's sql extension is called PL-SQL.
There are problems <br /> we can follow up the community mailing list, follow up to be finishing.
Http: // apache-spark-developers-l ... ad-safe-td7263.html
Http: //apache-spark-user-list.10 ... ark-SQL-td9538.html
Summary <br /> finishing above the implementation of the various modules of Spark SQL, code structure, the implementation process and their understanding of Spark SQL.
1, what features does Spark support?
2, Spark and Hadoop contrast is what?
3, how to understand Spark's logic implementation plan?
Catalyst
Catalyst is an independent library decoupled with Spark and is an impl-free implementation plan for the generation and optimization of the framework.
Currently coupled with the Spark Core, this user mail group was questioned, see mail.
The following is the architecture of Catalyst earlier, showing the code structure and processing flow.
Catalyst positioning <br /> Other systems If you want to do some classes based on Spark sql, standard sql or even other query language query, based on the Catalyst provided by the parser, the implementation of the planning tree structure, the logic of the implementation of the scheduling system rules and other systems To achieve the implementation of the plan analysis, generation, optimization, mapping work.
Corresponding to the above figure, mainly on the left side of the TreeNodelib and the middle of the transformation process involved in the class structure are provided by Catalyst. As for the right physical execution plan mapping generation process, the physical execution plan is based on the cost optimization model, the implementation of specific physical operators by the system itself.
Catalyst present <br /> in the parser is provided by a simple scala written sql parser, support semantics is limited, and should be the standard sql.
In terms of rules, the optimization rules provided are relatively basic (and Pig / Hive is not so rich), but some optimization rules are actually related to the specific physical operator, so some of the rules need to be developed and implemented in the system side (Such as SparkStrategy in spark-sql).
Catalyst also has its own set of data types.
Here are a few sets of important Catalyst class structure.
TreeNode system
TreeNode is the data structure represented by the Catalyst execution plan, is a tree structure with some scala collection operation capability and tree traversal capability. The tree is maintained in memory and will not be dumped to disk in a formatted file, and the tree is modified to replace the existing node, either during the logical execution plan or the optimized logic execution plan. The
TreeNode, with a children inside: Seq [BaseType] that child nodes, with foreach, map, collect and other methods for node operations, as well as transformDown (default, preorder traversal), transformUp such a traversal tree node, the implementation of matching nodes Change the method.
Provide UnaryNode, BinaryNode, LeafNode three trait, that is, non-leaf nodes allow one or two sub-nodes.
TreeNode provides a paradigm.
TreeNode has two subclass inheritance systems, QueryPlan and Expression. QueryPlan The following is a logical and physical execution plan two systems, the former in the Catalyst in a detailed realization, which needs to be implemented in the system itself. Expression is the expression system, the following chapters will be introduced.
Tree's transformation implementation:
Passed PartialFunction [TreeType, TreeType], if the match with the operator, the node will be replaced by the results, otherwise the node will not change. The whole process is recursively performed on children.
Execute the plan to represent the model
Logical execution plan
QueryPlan inherited from TreeNode, with an internal output: Seq [Attribute], with transformExpressionDown, transformExpressionUp method.
In Catalyst, the main subclass of QueryPlan is LogicalPlan, the logical execution plan representation. The physical execution plan is represented by the consumer (spark-sql project).
LogicalPlan inherits from QueryPlan with a reference: Set [Attribute], the main method is resolve (name: String): Option [NamedeExpression], used to analyze the corresponding NamedExpression.
LogicalPlan has many specific subclasses, also divided into UnaryNode, BinaryNode, LeafNode three categories, specifically in the org.apache.spark.sql.catalyst.plans.logical path.
Logical implementation plan implementation
LeafNode main subclass is Command system:
The semantics of each command can be seen from the subclass name, representing the non-query command that the system can execute, such as DDL.
Subclass of UnaryNode:
Subclass of BinaryNode:
Physical Execution Plan <br /> On the other hand, the physical execution plan node is implemented in a specific system, such as the SparkPlan inheritance system in the spark-sql project.
The physical execution plan implementation of each subclass to achieve execute () method, generally have the following subclass implementation (incomplete).
Subclass of LeadNode:
Subclass of UnaryNode:
Subclass of BinaryNode:
Refer to the physical execution plan and mention the partition representation model provided by Catalyst.
Perform a plan mapping
Catalyst also provides a QueryPlanner [Physical <: TreeNode [PhysicalPlan]] abstract class, the need for subclasses to develop a number of strategies: Seq [Strategy], the apply method is similar to the specific strategy developed according to the logic of the implementation of the plan operator mapping Physical execution plan operator. As the physical execution plan node is implemented in a specific system, so QueryPlanner and the inside of the strategy also need to be implemented in a specific system.
In the spark-sql project, SparkStrategies inherited QueryPlanner [SparkPlan], the internal development of the LeftSemiJoin, HashJoin, PartialAggregation, BroadcastNestedLoopJoin, CartesianProduct and several other strategies, each strategy is a LogicalPlan, generated Seq [SparkPlan] Each SparkPlan is understood as a specific RDD operator.
For example, in BasicOperators this Strategy, in a match-case match the way to deal with a lot of basic operators (one can directly mapped to RDD operator), as follows:
- Case logical.Project (projectList, child) =>
- Execution.Project (projectList, planLater (child)) :: Nil
- Case logical.Filter (condition, child) =>
- Execution.Filter (condition, planLater (child)) :: Nil
- Case logical.Aggregate (group, agg, child) =>
- Execution.Aggregate (partial = false, group, agg, planLater (child)) (sqlContext) :: Nil
- Case logical.Sample (fraction, withReplacement, seed, child) =>
- Execution.Sample (fraction, withReplacement, seed, planLater (child)) :: Nil
Expression system
Expression, that is, expression, that does not need to perform the engine calculation, and can directly calculate or deal with the node, including the Cast operation, Projection operation, four operations, logic operator operations.
You can refer to the class under org.apache.spark.sql.expressionspackage.
Rules System <br /> RulesExecutor [TreeType] abstract classes are required to inherit the execution plan tree (Analyze process, Optimize process, SparkStrategy process), implement rule matching and node processing.
RuleExecutor internally provides a Seq [Batch], which is defined by the RuleExecutor processing steps. Each Batch represents a set of rules that are equipped with a policy that describes the number of iterations (one or more times).
- Protected case class Batch (name: String, strategy: Strategy, rules: Rule [TreeType] *)
Rule [TreeType <: TreeNode [_]] is an abstract class that subclasses need to override the apply (plan: TreeType) method to formulate the processing logic.
RuleExecutor apply (plan: TreeType): The TreeType method will iterate over the nodes in the incoming plan according to the batches order and the Rules order in the batch. The processing logic is implemented by the concrete Rule subclass.
Hive related
Hive support
Spark SQL support for hive is a separate spark-hive project, support for Hive includes HQL query, hive metaStore information, hive SerDes, hive UDFs / UDAFs / UDTFs, similar to Shark.
Only in the HiveContext under the hive api obtained from the data set, you can use hql query, the analysis of its hql is dependent on the org.apache.hadoop.hive.ql.parse.ParseDriver class parse method to generate Hive AST.
In fact sql and hql, not with the support. Can be understood as hql is independent support, can be hql query data set must be read from the hive api. The following figure in the parquet, json and other file support only occurred in the sql environment (SQLContext).
Hive on Spark
Hive official made Hive onSpark's JIRA. Shark after the end, split into two directions:
Spark SQL is now on the Hive support, reflected in the reuse of the Hive meta store data, hql parsing, UDFs, SerDes, in the implementation of DDL and some simple commands, the tune is hive client. Hql translation will deal with some of the query principal has nothing to do with the set, cache, addfile and other commands, and then call ParserDriver translation hql, and AST into Catalyst LogicalPlan, follow-up optimization, physical execution plan translation and implementation process, and Sql used the same Is the content provided by Catalyst, the implementation engine is Spark. Throughout the binding process, ASTNode is mapped to LogicalPlan as the focus.
And Hive community Hive on Spark will be how to achieve, the specific reference jira in the design documents.
Contrast with Shark,
Shark relies heavily on Hive's execution plan related modules and CLI. The CLI and JDBC sections are supported by Spark SQL follow-up. Shark additional provision of the Table data row column, serialization, compression memory module, also received the Spark Sql sql project.
The above describes the difference between Shark and Spark SQL Hive, Shark inheritance of this project understanding.
The Spark SQL Hive and Hive community Hive on Spark the need for a specific reference jira in the design of the document, I have not read.
Spark-hive works
Analysis process
HiveQl.parseSql () Hql resolved into logicalPlan. Parse the process, extract some commands, including:
2 set key = value
2 cache table
2 uncache table
2 add jar
2 add file
2 dfs
2 source
And then by Hive's ParseDriver Hql resolved into AST, get ASTNode,
- Def getAst (sql: String): ASTNode = ParseUtils.findRootNonNullToken ((new parseDriver) .parse (sql))
The Node into the Catalyst LogicalPlan, conversion logic is more complex, but also Sparksql support the most critical part of hql. See HiveQl.nodeToPlan (node: Node) for details: LogicalPlan method.
The approximate conversion logic includes:
Handle TOK_EXPLAIN and TOK_DESCTABLE
Handle TOK_CREATETABLE, including the set of tables to create a set of table set TOK_XXX
Handle TOK_QUERY, including TOK_SELECT, TOK_WHERE, TOK_GROUPBY, TOK_HAVING, TOK_SORTEDBY, TOK_LIMIT, etc., and nodeToRelation of the statement followed by FROM.
Handle TOK_UNION
Hive AST tree structure and that are not familiar, so here omitted.
Analyze the process
Metadata interaction
Catalog class for the HiveMetastoreCatalog, through the hive conf generated client (org.apache.hadoop.hive.ql.metadata.Hive, used to communicate with MetaStore, access to metadata and DDL operation), catalog lookupRelation method inside, client.getTable ( Get the table information, client.getAddPartitionsForPruner () get the partition information.
Udf related
FunctionRegistry class HiveFunctionRegistry, according to the method name, through the hive related class to query the method, check whether the method is UDF, or UDAF (aggregation), or UDTF (table). Here only udf inquiries, do not do the new method include.
The inheritance relationship with Catalyst's Expression is as follows:
Inspector related
HiveInspectors provides several methods for mapping data types and ObjectInspetor subclasses, including PrimitiveObjectInspector, ListObjectInspector, MapObjectInspector, and StructObjectInspector
Optimizer process <br /> before making the optimization , will try to generate a logical execution plan for the createtabl operation, because the implementation of the hql may be "CREATE TABLE XXX", this part of the processing HiveMetastoreCatalog CreateTables single case, inherited the Rule [LogicalPlan].
And PreInsertionCasts processing, but also HiveMetastoreCatalog in a single case, inherited the Rule [LogicalPlan].
After the optimizer process with the SQLContext, with the same Catalyst provided Optimizer class.
Planner and the implementation process
HiveContext inherits from SQLContext, and its QueryExecution also inherits from QueryExecution from SQLContext. Subsequent execution plan optimization, physical execution plan translation, processing and implementation process is consistent with the SQL processing logic.
Translation of the physical implementation plan, hive planner developed a specific strategy, and SparkPlanner slightly different.
More Scripts, DataSinks, HiveTableScans, and HiveCommandStrategy have four strategies for handling physical execution plans (see HiveStrategies).
1. Scripts, used to deal with the kind of hive command line execution script. Implementation is the use of ProcessBuilder new JVM process from the way, "/ bin / bash-c scripts" way to execute the script and get the output stream data, into the Catalyst Row data format.
2. DataSinks, used to write data to the case of the Hive table. Which involves some hive read and write data format conversion, serialization, read configuration and so on, and finally through the SparkContext runJob interface, submit the job.
3. HiveTableScans, used to scan the hive table, support the use of predicate partition clipping (Partition pruning predicates are detected and applied).
4. HiveCommandStrategy, used to execute native command and describe command. I understand that this order is directly transferred hive client stand-alone implementation, because it may only deal with meta data.
ToRDD: RDD [Row] processing is also a little different, return RDD [Row], when each element made a copy.
SQL Core
Spark SQL is the core of the existing RDD, with Schema information, and then registered as sql Lane "Table", its sql query. This is mainly divided into two parts, one is generated SchemaRD, the second is the implementation of the query.
Generate SchemaRDD
If it is spark-hive project, then read the metadata information as a Schema, read the process of data on the hdfs to Hive completed, and then according to the two parts generated SchemaRDD, HiveContext under the hql () query.
For Spark SQL,
In terms of data, RDD can come from any existing RDD, or from supported third-party formats such as json file, parquet file.
SQLContext will implicitly convert RDD with case class into SchemaRDD
- Implicit def createSchemaRDD [A <: Product: TypeTag] (rdd: RDD [A]) =
- New SchemaRDD (this,
- SparkLogicalPlan (ExistingRdd.fromProductRdd (rdd)))
ExsitingRdd will reflect the case class attributes, and the RDD data into Catalyst's GenericRow, and finally return RDD [Row], that is, a SchemaRDD. Here the specific transformation logic can refer to ExsitingRdd's productToRowRdd and convertToCatalyst methods.
After the SchemaRDD can be provided by the registration table operation, for the Schema replication part of the RDD conversion operations, DSL operations, saveAs operations and so on.
Row and GenericRow are the row representation models in Catalyst
Row uses Seq [Any] to represent values, GenericRow is a subclass of Row, representing values with an array. Row supports data types including Int, Long, Double, Float, Boolean, Short, Byte, String. Supports reading the value of a column in ordinal. Before reading the need to do isNullAt (i: Int) to judge.
Each has a Mutable class that provides setXXX (i: int, value: Any) to modify the value on an ordinal.
Hierarchy
The following figure roughly compares Pig, Spark SQL, Shark in the realization of the level of the difference, only for reference.
Query flow
SQLContext Lane on the analysis of sql and the implementation of the process:
1. The first step parseSql (sql: String), simple sql parser grammar parsing, generate LogicalPlan.
2. The second step analyzer (logicalPlan), to complete the lexical syntax analysis of the implementation of the initial analysis and mapping,
The current Analyzer in SQLContext is provided by Catalyst and is defined as follows:
New Analyzer (catalog, EmptyFunctionRegistry, caseSensitive = true)
Catalog for SimpleCatalog, catalog is used to register table and query relation.
And here the FunctionRegistry does not support the lookupFunction method, so the analyzer does not support Function registration, that is, UDF.
Several rules are defined in Analyzer:
- Val batches: Seq [Batch] = Seq (
- Batch ("MultiInstanceRelations", Once,
- NewRelationInstances),
- Batch ("CaseInsensitiveAttributeReferences", Once,
- (If (caseSensitive) Nil else LowercaseAttributeReferences :: Nil): _ *),
- Batch ("Resolution", fixedPoint,
- ResolveReferences ::
- ResolveRelations ::
- NewRelationInstances ::
- ImplicitGenerate ::
- StarExpansion ::
- ResolveFunctions ::
- GlobalAggregates ::
- TypeCoercionRules: _ *),
- Batch ("Check Analysis", Once,
- CheckResolution),
- Batch ("AnalysisOperators", fixedPoint,
- EliminateAnalysisOperators
- )
3. From the second step is the initial logicalPlan, followed by the third step is optimizer (plan).
Optimizer which also defines a number of rules, will be in order to optimize the implementation of the plan.
- Val batches =
- Batch ("Combine Limits", FixedPoint (100),
- CombineLimits) ::
- Batch ("ConstantFolding", FixedPoint (100),
- NullPropagation,
- ConstantFolding,
- LikeSimplification,
- BooleanSimplification,
- SimplifyFilters,
- SimplifyCasts,
- SimplifyCaseConversionExpressions) ::
- Batch ("Filter Pushdown", FixedPoint (100),
- CombineFilters,
- PushPredicateThroughProject,
- PushPredicateThroughJoin,
- ColumnPruning) :: Nil
4. Optimized execution plan, but also to the SparkPlanner processing, which defines a number of strategies, the purpose is based on the logical implementation of the tree to generate the final implementation of the physical execution plan tree, that is, SparkPlan.
- Val strategies: Seq [Strategy] =
- CommandStrategy (self) ::
- TakeOrdered ::
- PartialAggregation ::
- LeftSemiJoin ::
- HashJoin ::
- InMemoryScans ::
- ParquetOperations ::
- BasicOperators ::
- CartesianProduct ::
- BroadcastNestedLoopJoin :: Nil
5. In the final implementation of the actual implementation of the physical plan, and finally to the two rules, SQLContext definition of this process is called prepareExExution, this step is an additional increase, directly new RuleExecutor [SparkPlan] carried out.
- Val batches =
- Batch ("Add exchange", Once, AddExchange (self)) ::
- Batch ("Prepare Expressions", Once, new BindReferences [SparkPlan]) :: Nil
6. Finally call SparkPlan execute () to perform the calculation. This execute () is defined in the implementation of each SparkPlan, which normally recursively calls children's execute () method, so it triggers the calculation of the whole tree.
Other features
Memory column storage
SQLContext cache / uncache table will be called when the column storage module.
The module from the Shark, the purpose is to table data cache in the memory when the line to do the operation, in order to compress.
Implementation class
The InMemoryColumnarTableScan class is an implementation of the SparkPlan LeafNode, which is a physical execution plan. Pass a SparkPlan (a confirmed physical execution) and a sequence of attributes that contain a row of rows that trigger the process of calculating and caching (and lazy).
ColumnBuilder writes data to ByteBuffer from different subclasses for different data types (boolean, byte, double, float, int, long, short, string). Corresponding to the ColumnAccessor is to access the column, turn it back to Row.
CompressibleColumnBuilder and CompressibleColumnAccessor is a compressed row and column converter builder whose ByteBuffer internal storage structure is as follows
[Java] view plaincopy View the code slice on CODE to my code slice
* .--------------------------- Column type ID (4 bytes)
* | .----------------------- Null count N (4 bytes)
* | | .------------------- Null positions (4 x N bytes, empty if null count is zero)
* | | | .------------- Compression scheme ID (4 bytes)
* | | | | .- Compressed non-null elements
* V V V V V
* + --- + --- + ----- + --- + --------- +
* | | | ... | | ... ...
* + --- + --- + ----- + --- + --------- +
* \ ----------- / \ ----------- /
* Header body
The CompressionScheme subclass is a different compression implementation
Are scala implementation, not with third-party library. Different implementations specify the supported column data type. In the build (), will compare each compression, select the minimum compression rate (if still greater than 0.8 is not compressed).
Here the estimation logic, from the subclass implementation of the gatherCompressibilityStats method.
Cache logic
Cache, you need to first of this cache table of the physical implementation plan generated.
In the cache process, InMemoryColumnarTableScan did not trigger the implementation, but generated in the InMemoryColumnarTableScan for the physical implementation of the plan SparkLogicalPlan, and the table into the plan.
In fact, when the cache, the first to catalog to find the table of information and table implementation of the plan, and then will be implemented (the implementation of the implementation of the physical implementation plan), and then put the table back to the catalog to maintain up, this time the implementation of The plan is already the final implementation of the physical execution plan. But at this time Columner module-related conversion and other operations are not triggered.
The real trigger is still in the execute () time, with the other SparkPlan execute () method to trigger the scene is the same.
Uncache logic
UncacheTable, in addition to delete the table table information, but also called InMemoryColumnarTableScan the cacheColumnBuffers method, get RDD collection, and unpersist () operation. CacheColumnBuffers mainly to the RDD each partition in the ROW of each Field to the ColumnBuilder.
UDF (not supported)
As in the previous analysis of SQLContext Lane Analyzer, the FunctionRegistry did not implement the lookupFunction.
In the spark-hive project, HiveContext Lane is to achieve the FunctionRegistry the trait, which is implemented as HiveFunctionRegistry, the realization of logic see org.apache.spark.sql.hive.hiveUdfs
Parquet supports <br /> to be collated
Http://parquet.io/
Specific Docs and Codes:
Https://github.com/apache/incubator-parquet-format
Https://github.com/apache/incubator-parquet-mr
Http://www.slideshare.net/julienledem/parquet-hadoop-summit-2013
JSON support
SQLContext, the increase jsonFile read method, and now look at the code to achieve isoop textfile read, that is, the json file should be on the HDFS. Specific json file loading, InputFormat is TextInputFormat, key class is LongWritable, value class is Text, and finally get the value of that part of the String content, that is, RDD [String].
In addition to jsonFile, also supports jsonRDD, example:
Http://spark.apache.org/docs/lat ... .html # json-datasets
After reading the json file, convert it to SchemaRDD. JsonRDD.inferSchema (RDD [String]) in a detailed analysis of the json and mapping out the schema process, and finally get the json LogicalPlan.
Json's parsing uses the FasterXML / jackson-databind library, the GitHub address , the wiki
Map the data into Map [String, Any]
Json's support enriches Spark SQL data access scenarios.
JDBC support
Jdbc support branchis under going
SQL92
Spark SQL The current SQL syntax support is available in the SqlParser class. The goal is to support SQL92? The
1. Basic applications, sql server and oracle are followed sql 92 grammar standards .
2. Practical applications, we will exceed the above criteria, the use of various database vendors have provided a wealth of custom standard library and syntax.
3. Microsoft sql server sql extension called T-SQL (Transcate SQL).
4. Oracle's sql extension is called PL-SQL.
There are problems <br /> we can follow up the community mailing list, follow up to be finishing.
Http: // apache-spark-developers-l ... ad-safe-td7263.html
Http: //apache-spark-user-list.10 ... ark-SQL-td9538.html
Summary <br /> finishing above the implementation of the various modules of Spark SQL, code structure, the implementation process and their understanding of Spark SQL.
Commentaires
Enregistrer un commentaire