Spark sql operation postgresql database [with source code]
Source git address
Complete project source code github
Spark sql support multiple data sources, for example, sparkSQL can be derived from multiple data sources: jsonFile, parquetFile, hive, etc., the following is postgresql.
 1. First create a test table in postgreSQL and insert the data. 1.1. Under postgres users in postgreSQL, create products
1. First create a test table in postgreSQL and insert the data. 1.1. Under postgres users in postgreSQL, create products
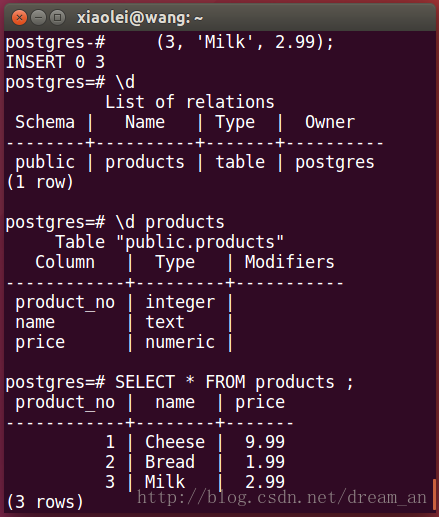
1.2. Insert data in products
View the database write results.
2. Write SPARK program. 2.1. Read Postgresql a table of data for the DataFrame
SparkPostgresqlJdbc.java
2.2. Write a Postgresql table
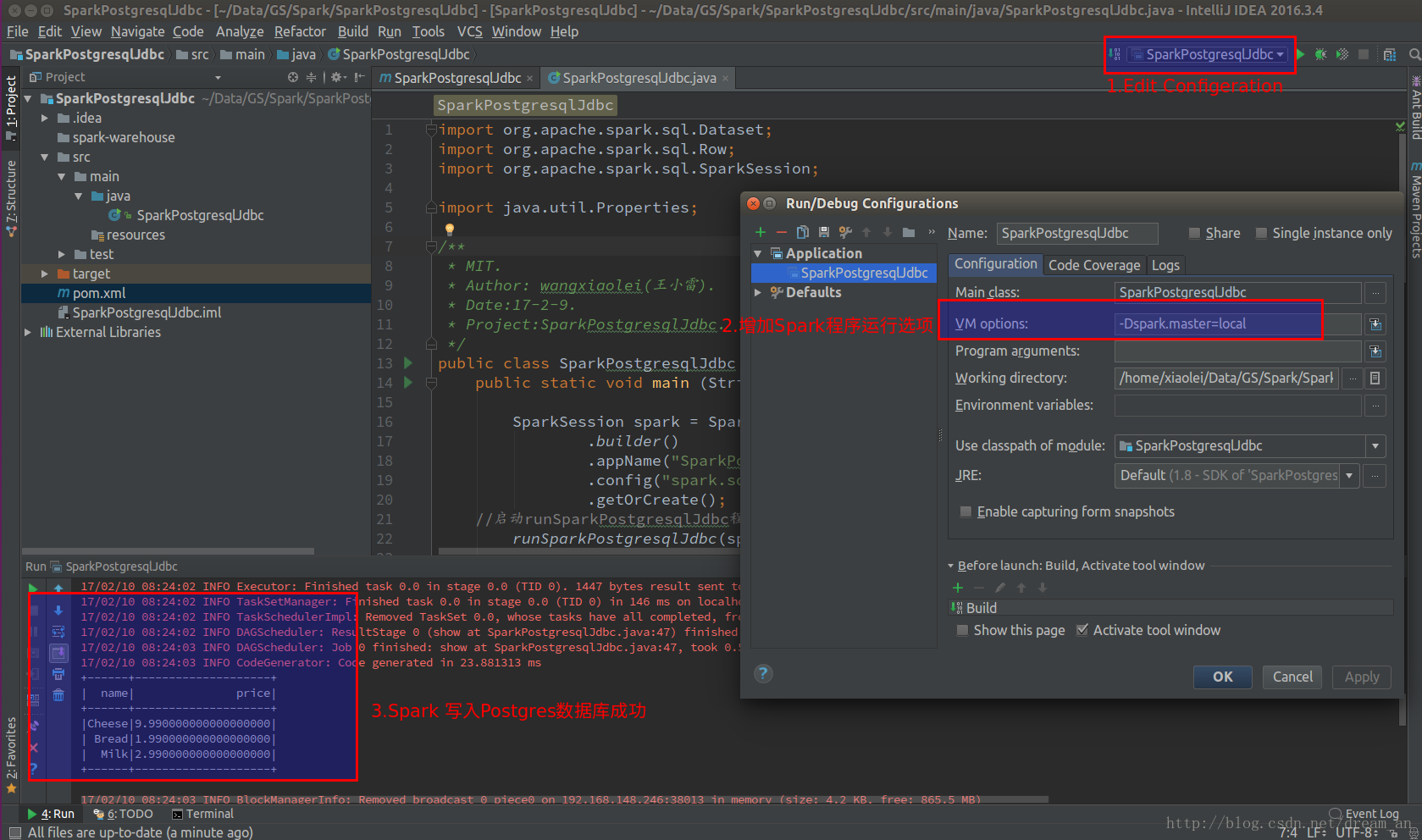
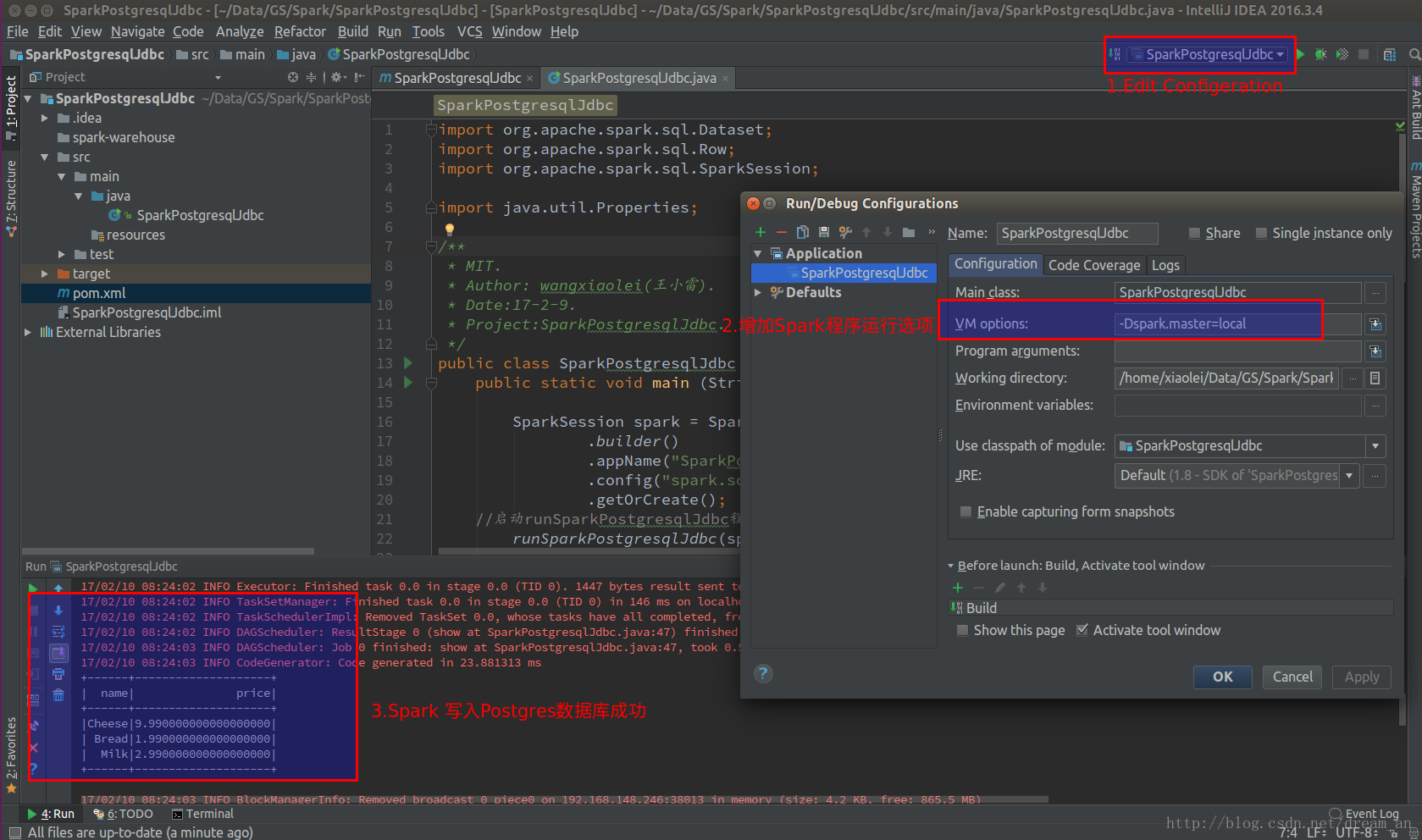
3. Run the program and view the results
3.1. Run directly in intellij IDEA (Community Edition).
A. Add "-Dspark.master = local" to the VM option in the "Edit Configeration" of the run button
3.2. Run in Terminal.

4. The following is the main source in the project
4.1. Project configuration source pom.xml
4.2.java source code
SparkPostgresqlJdbc.java
Complete project source code github
Spark sql support multiple data sources, for example, sparkSQL can be derived from multiple data sources: jsonFile, parquetFile, hive, etc., the following is postgresql.
Overview: Spark postgresql jdbc database connection and write operation
source code, a detailed record of the operation of the database
SparkSQL, through the Java program, in the local development and
operation. Overall, Spark builds a database connection, reads data, writes DataFrame data to another database table. With complete project source code ( complete project source code github ).
[Bash shell] plain text view copy code
CREATE TABLE products ( Product_no integer, Name text, Price numeric );
1.2. Insert data in products
[Bash shell] plain text view copy code
INSERT INTO products (product_no, name, price) VALUES (1, 'Cheese', 9.99), (2, 'Bread', 1.99), (3, 'Milk', 2.99)
View the database write results.
2. Write SPARK program. 2.1. Read Postgresql a table of data for the DataFrame
SparkPostgresqlJdbc.java
[Java] plain text view copy code
Properties connectionProperties = new Properties (); / / Increase the database user name (user) password (password), specify the postgresql driver (driver) ConnectionProperties.put ("user", "postgres"); ConnectionProperties.put ("password", "123456"); ConnectionProperties.put ("driver", "org.postgresql.Driver"); // SparkJdbc Read Postgresql products table contents Dataset <Row> jdbcDF = spark.read () .jdbc ("jdbc: postgresql: // localhost: 5432 / postgres", "products", connectionProperties) .select ("name", "price"); // show jdbcDF data content jdbcDF.show ();
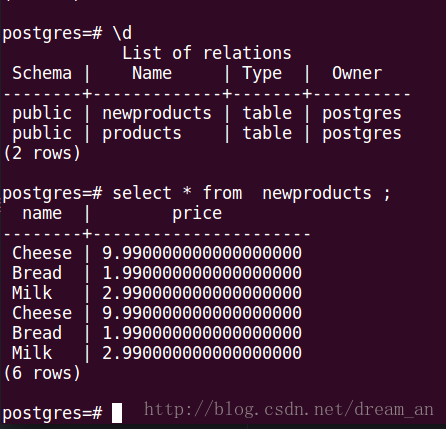
2.2. Write a Postgresql table
[Java] plain text view copy code
/ / JdbcDF new data and write newproducts, append mode is the connection mode, the default is "error" mode. JdbcDF.write (). Mode ("append") .jdbc ("jdbc: postgresql: // localhost: 5432 / postgres", "newproducts", connectionProperties);
3. Run the program and view the results
3.1. Run directly in intellij IDEA (Community Edition).
A. Add "-Dspark.master = local" to the VM option in the "Edit Configeration" of the run button
3.2. Run in Terminal.
[Bash shell] plain text view copy code
/opt/spark-2.1.0-bin-hadoop2.7/bin/spark-submit \ --class "SparkPostgresqlJdbc" \ --master local [4] \ --driver-class-path /home/xiaolei/.m2/repository/org/postgresql/postgresql/9.4.1212/postgresql-9.4.1212.jar \ Target / SparkPostgresqlJdbc-1.0-SNAPSHOT.jar
Where --driver-class-path specifies the downloaded postgresql JDBC
database driver path, and the command is executed in the project's root
directory (/ home / xiaolei / Data / GS / Spark / SparkPostgresqlJdbc).
View the data that Spark writes to the database
4. The following is the main source in the project
4.1. Project configuration source pom.xml
[XML] plain text view copy code
<? Xml version = "1.0" encoding = "UTF-8"?> <Project xmlns = "http://maven.apache.org/POM/4.0.0" Xmlns: xsi = "http://www.w3.org/2001/XMLSchema-instance" Xsi: schemaLocation = "http://maven.apache.org/POM/4.0.0 [url = http: //maven.apache.org/xsd/maven-4.0.0.xsd] http: //maven.apache .org / xsd / maven-4.0.0.xsd [/ url] "> <ModelVersion> 4.0.0 </ modelVersion> <GroupId> wangxiaolei </ groupId> <ArtifactId> SparkPostgresqlJdbc </ artifactId> <Version> 1.0-SNAPSHOT </ version> <Dependencies> <Dependency> <! - Spark dependency -> <GroupId> org.apache.spark </ groupId> <ArtifactId> spark-core_2.11 </ artifactId> <Version> 2.1.0 </ version> </ Dependency> <Dependency> <GroupId> org.apache.spark </ groupId> <ArtifactId> spark-sql_2.11 </ artifactId> <Version> 2.1.0 </ version> </ Dependency> <Dependency> <GroupId> org.postgresql </ groupId> <ArtifactId> postgresql </ artifactId> <Version> 9.4.1212 </ version> </ Dependency> </ Dependencies> </ Project>
4.2.java source code
SparkPostgresqlJdbc.java
[Java] plain text view copy code
Import org.apache.spark.sql.Dataset; Import org.apache.spark.sql.Row; Import org.apache.spark.sql.SparkSession; Import java.util.Properties; / ** * MIT. * Author: wangxiaolei (Wang Xiaolei). * Date: 17-2-9. * Project: SparkPostgresqlJdbc. * / Public class SparkPostgresqlJdbc { Public static void main (String [] args) { SparkSession spark = SparkSession .builder () .appName ("SparkPostgresqlJdbc") .config ("spark.some.config.option", "some-value") .getOrCreate (); // start runSparkPostgresqlJdbc program runSparkPostgresqlJdbc (spark); Spark.stop (); } Private static void runSparkPostgresqlJdbc (SparkSession spark) { // new a property System.out.println ("make sure the database is already open and create the products table and insert the data"); Properties connectionProperties = new Properties (); / / Increase the database user name (user) password (password), specify the postgresql driver (driver) System.out.println ("increase the database user name (user) password (password), specify the postgresql driver (driver)"); ConnectionProperties.put ("user", "postgres"); ConnectionProperties.put ("password", "123456"); ConnectionProperties.put ("driver", "org.postgresql.Driver"); // SparkJdbc read Postgresql products table content System.out.println ("SparkJdbc read Postgresql products table content"); Dataset <Row> jdbcDF = spark.read () .jdbc ("jdbc: postgresql: // localhost: 5432 / postgres", "products", connectionProperties) .select ("name", "price"); // show jdbcDF data content jdbcDF.show (); / / JdbcDF new data and write newproducts, append mode is the connection mode, the default is "error" mode. JdbcDF.write (). Mode ("append") .jdbc ("jdbc: postgresql: // localhost: 5432 / postgres", "newproducts", connectionProperties); } }



Thank you for sharing this post,and this article very useful for me.
RépondreSupprimerkeep sharing more articles with us.
big data hadoop training