Let you really understand what is SparkContext, SQLContext and HiveContext
The
first step spark driver application creates SparkContext, SparkContext
allows the spark driver application to access the cluster through the
resource manager. The resource manager can be Yarn, or the spark cluster manager.
In order to create SparkContext, you can first create SparkConf,
SparkConf stored configuration information, Spark driver application
will be passed to SparkContext. Some parameters define the Spark driver application properties and are used to allocate cluster resources. Such as worker nodes running executors number, memory size and cores. The Spark driver application can be customized with setAppName (). You can view spark1.3.1 to get the full parameters of sparkconf. SparkConf documentation ( http://spark.apache.org/docs/1.3.1/api/scala/index.html )
Now we have SparkConf that can be passed to SparkContext, so our application knows how to access the cluster.
Now your Spark driver application has SparkContext, which knows to use and request cluster resources. If you are using YARN, hadoop's resourcemanager (headnode) and nodemanager (workernode) will allocate container for executors. If the resource is valid, the executors on the cluster will allocate memory and cores according to the configuration parameters. If you use the Sparks Cluster Manager, SparkMaster (headnode) and SparkSlave (workernode) will use the assignors assigned to it. The following diagram shows the driver between them, the cluster resource manager and the executors relationship

Each spark driver application has its own executors on the cluster. The cluster remains running as long as the spark driver application has SparkContext. Executors run the user code, run the calculation and cache the application's data. SparkContext Creates a job, broken down into stages.
SparkSQL is a module of spark, SparkSQL used to deal with structured data, so SparkSQL your data must define the schema. In spark1.3.1, sparksql inherited dataframes and a SQL query engine. SparkSQL has SQLContext and HiveContext.HiveContext inherited SQLContext.Hortonworks and the Spark community recommend using HiveContext. You can see the following, when you run the spark-shell, it interacts with the driver application, he will automatically create SparkContext defined as sc and HiveContext Defined as sqlContext.HiveContext allows the implementation of sql query and Hive command .pyspark also. You can look at the Spark 1.3.1 documentation, SQLContext and HiveContext in the SQLContext documentation and HiveContext documentation ( http://spark.apache.org/docs/1.3.1/api/scala/index.html#package )
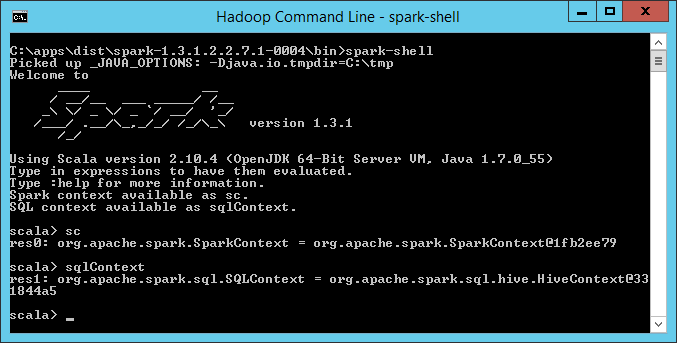
From the above, SparkContext is actually connected to the cluster and get spark configuration file information, and then run in the cluster.
SQLContext and HiveContext
SQLContext: spark handles the import of structured data. Allows creation of DataFrame and sql queries for more viewable
Link ( http://spark.apache.org/docs/1.3 ... park.sql.SQLContext )
HiveContext: spark sql execution engine, integrated hive data, read in the classpath hive-site.xml configuration file configuration Hive
More viewable
Link ( http://spark.apache.org/docs/1.3 ... ql.hive.HiveContext )
[Scala] plain text view copy code
Import org.apache.spark.SparkConf ("Spark: // master: 7077") .set ("spark.executor.memory", "2g") .setset = "SparkConf ()
Now we have SparkConf that can be passed to SparkContext, so our application knows how to access the cluster.
[Scala] plain text view copy code
Import org.apache.spark.SparkConf Import org.apache.spark.SparkContext ("Spark: // master: 7077") .set ("spark.executor.memory", "2g") .setset = "SparkConf () Val sc = new SparkContext (conf)
Now your Spark driver application has SparkContext, which knows to use and request cluster resources. If you are using YARN, hadoop's resourcemanager (headnode) and nodemanager (workernode) will allocate container for executors. If the resource is valid, the executors on the cluster will allocate memory and cores according to the configuration parameters. If you use the Sparks Cluster Manager, SparkMaster (headnode) and SparkSlave (workernode) will use the assignors assigned to it. The following diagram shows the driver between them, the cluster resource manager and the executors relationship
Each spark driver application has its own executors on the cluster. The cluster remains running as long as the spark driver application has SparkContext. Executors run the user code, run the calculation and cache the application's data. SparkContext Creates a job, broken down into stages.
SparkSQL is a module of spark, SparkSQL used to deal with structured data, so SparkSQL your data must define the schema. In spark1.3.1, sparksql inherited dataframes and a SQL query engine. SparkSQL has SQLContext and HiveContext.HiveContext inherited SQLContext.Hortonworks and the Spark community recommend using HiveContext. You can see the following, when you run the spark-shell, it interacts with the driver application, he will automatically create SparkContext defined as sc and HiveContext Defined as sqlContext.HiveContext allows the implementation of sql query and Hive command .pyspark also. You can look at the Spark 1.3.1 documentation, SQLContext and HiveContext in the SQLContext documentation and HiveContext documentation ( http://spark.apache.org/docs/1.3.1/api/scala/index.html#package )
From the above, SparkContext is actually connected to the cluster and get spark configuration file information, and then run in the cluster.
SQLContext and HiveContext
SQLContext: spark handles the import of structured data. Allows creation of DataFrame and sql queries for more viewable
Link ( http://spark.apache.org/docs/1.3 ... park.sql.SQLContext )
HiveContext: spark sql execution engine, integrated hive data, read in the classpath hive-site.xml configuration file configuration Hive
More viewable
Link ( http://spark.apache.org/docs/1.3 ... ql.hive.HiveContext )



Great and nice article,keep sharing more articles with us.
RépondreSupprimerbig data and hadoop online training