Spark Streaming uses Kafka to ensure zero data loss
Spark
streaming from the beginning of the data provided by the zero loss,
want to enjoy this feature, you need to meet the following conditions:
Reliable sources and receivers
Spark streaming can be received by receivers in a variety of ways as data sources (including kafka), stored in spark by replication (for faultolerance, default to two spark executors), and if data replication is complete, the receivers know Kafka update offsets to zookeeper). So that when the receivers in the process of receiving data crash, there will be no data loss, receivers do not copy the data, when the receiver recovered after the resumption.
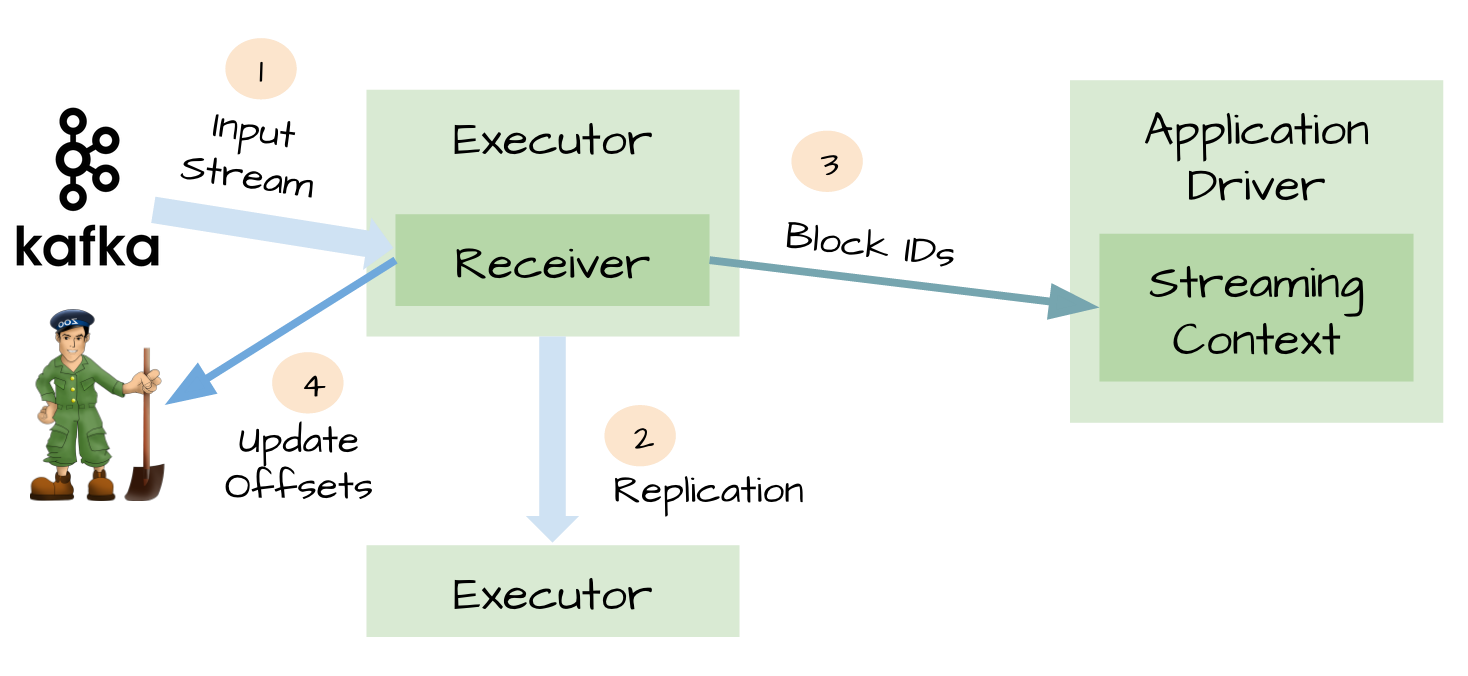
Metadata checkpoint
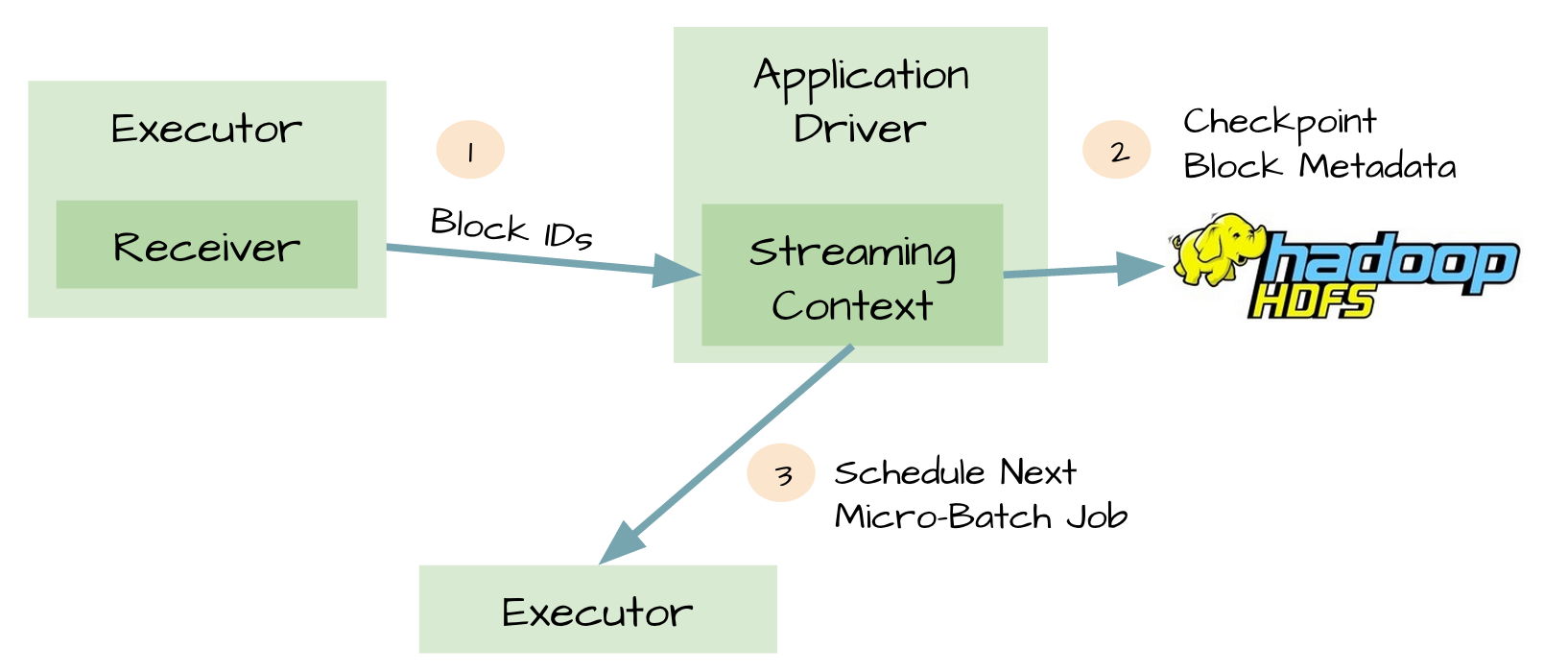
Reliable sources and receivers can make the data recover after the receivers fail, but after the driver fails to recover is more complicated, one way is through the checkpoint metadata to HDFS or S3. Metadata includes:
So when the driver fails, you can through the metadata checkpoint, refactoring the application and know that the implementation to that place.
Data may be lost in the scene
Reliable sources and receivers, and metadata checkpoint can not guarantee that data is not lost, for example:
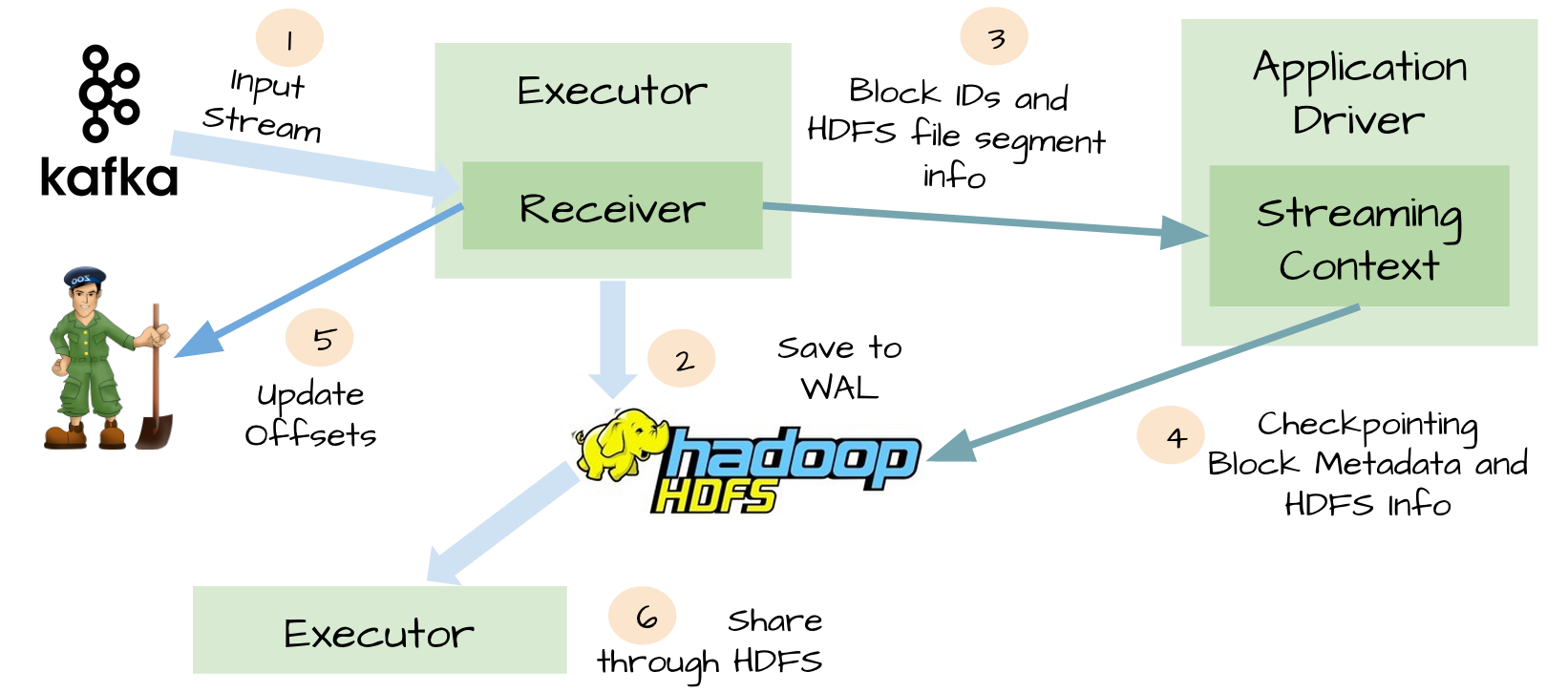
WAL
In order to avoid the above scenario, spark streaming 1.2 introduces WAL. All the received data through the receivers written HDFS or S3 checkpoint directory, so that when the driver fails, executor data is lost, you can checkpoint recovery.
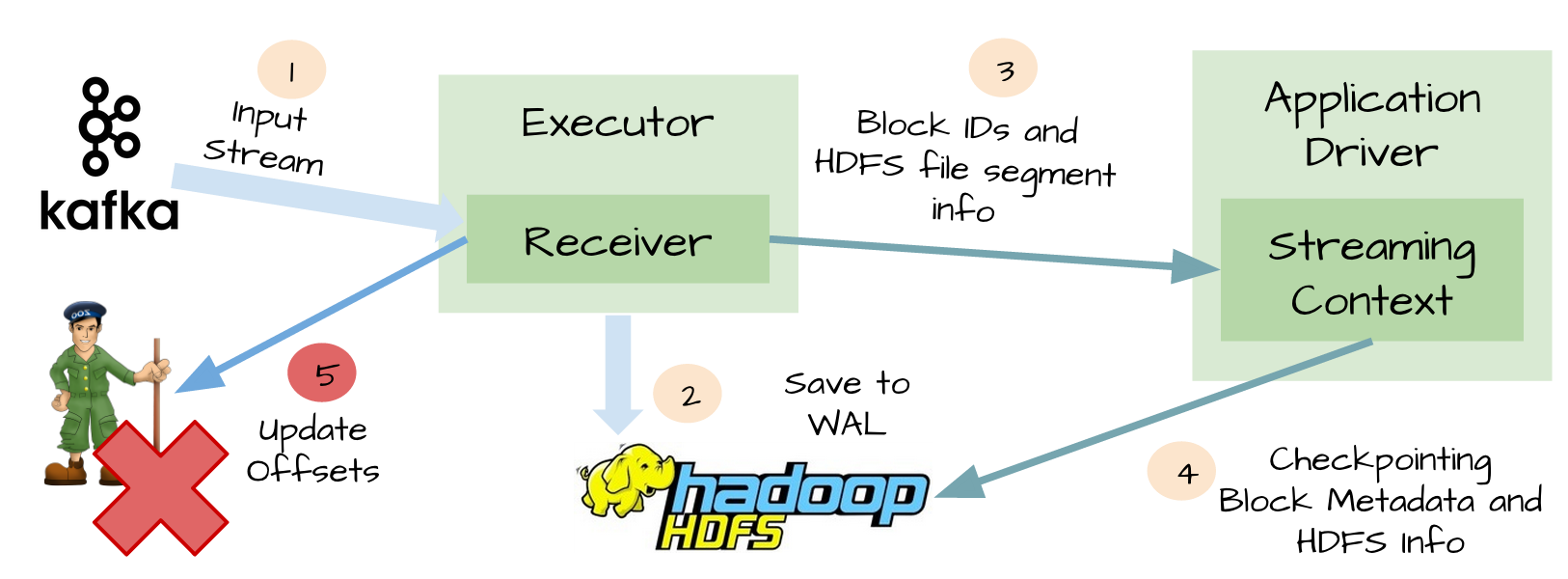
At-Least-Once
Although WAL can guarantee data zero loss, but can not guarantee exactly-once, for example, the following scenario:
WAL shortcomings
Through the above description, WAL has two shortcomings:
Reducing the performance of receivers, because the data should also be stored to HDFS and other distributed file system
For some resources, there may be duplicate data, such as Kafka, there is a data in Kafka, and there is a copy of the Spark Streaming (stored in the Hado API-compatible file system in the form of WAL)
Kafka direct API
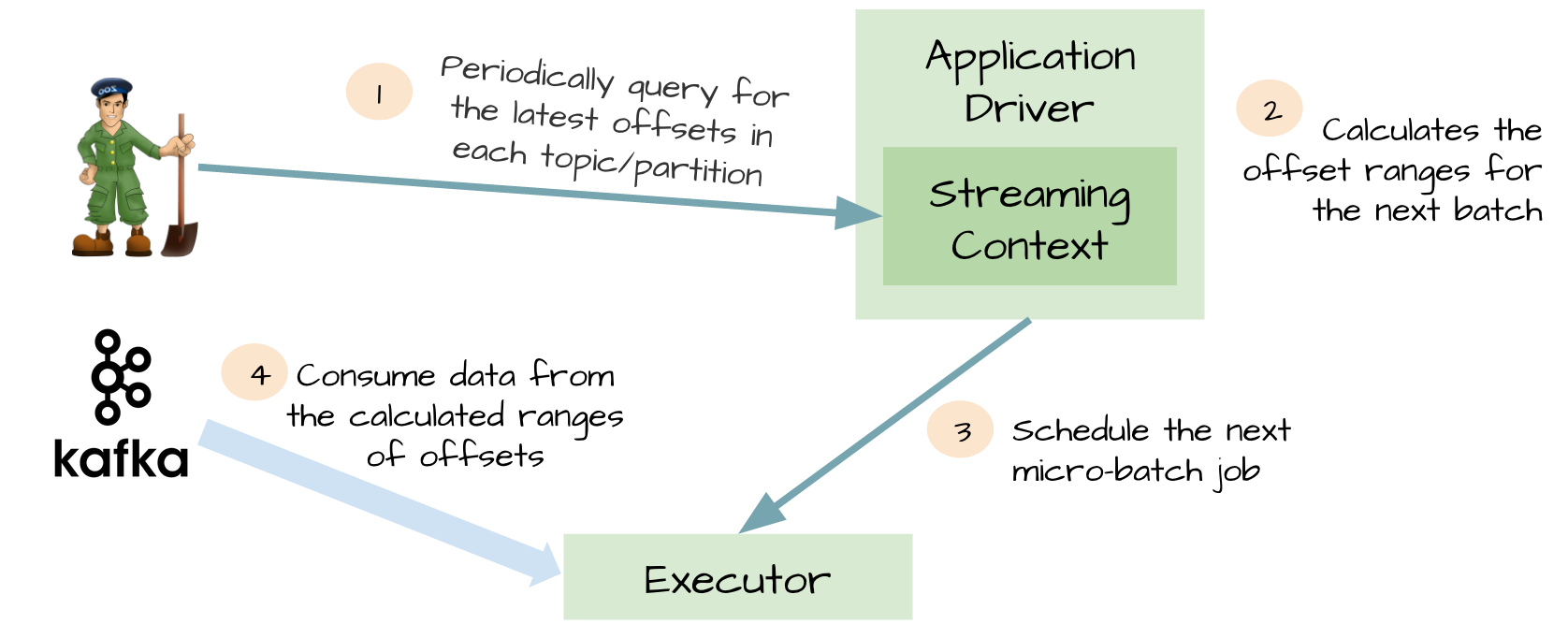
For the loss of performance of WAL and exactly-once, spark streaming1.3 uses the Kafka direct API. Very clever, Spark driver to calculate the next batch offsets, directing executor consumption corresponding topics and partitions. Consuming Kafka news, just like consuming a file system file.
to sum up
Mainly to say that spark streaming through a variety of ways to ensure that the data is not lost, and ensure exactly-once, each version are spark streaming more and more stable, more and more to the production environment to use the development.
reference
Spark-streaming Recent Evolution of Zero Data Loss Guarantee in Spark Streaming With Kafka
Kafka direct API
Spark streaming
Original link: https://github.com/jacksu/utils4 ... / md / spark_streaming Use kafka to ensure data zero
- Data entry requires reliable sources and reliable receivers
- Application metadata must be applied by driver checkpoint
- WAL (write ahead log)
Reliable sources and receivers
Spark streaming can be received by receivers in a variety of ways as data sources (including kafka), stored in spark by replication (for faultolerance, default to two spark executors), and if data replication is complete, the receivers know Kafka update offsets to zookeeper). So that when the receivers in the process of receiving data crash, there will be no data loss, receivers do not copy the data, when the receiver recovered after the resumption.
Metadata checkpoint
Reliable sources and receivers can make the data recover after the receivers fail, but after the driver fails to recover is more complicated, one way is through the checkpoint metadata to HDFS or S3. Metadata includes:
- Configuration
- Code
- Some queued waiting but not completed RDD (only metadata, not data)
So when the driver fails, you can through the metadata checkpoint, refactoring the application and know that the implementation to that place.
Data may be lost in the scene
Reliable sources and receivers, and metadata checkpoint can not guarantee that data is not lost, for example:
- Two executors get the calculated data and save them in their memory
- Receivers know that the data has been entered
- Executors began to calculate the data
- Driver suddenly failed
- Driver failed, then executors will be killed off
- Because the executor was killed, then their memory data will be lost, but these data are no longer processed
- The data in the executor is unrecoverable
WAL
In order to avoid the above scenario, spark streaming 1.2 introduces WAL. All the received data through the receivers written HDFS or S3 checkpoint directory, so that when the driver fails, executor data is lost, you can checkpoint recovery.
At-Least-Once
Although WAL can guarantee data zero loss, but can not guarantee exactly-once, for example, the following scenario:
- Receivers receives the data and saves it to HDFS or S3
- Before updating offset, receivers failed
- Spark Streaming thought the data was successful, but Kafka thought the data was not received successfully because offset was not updated to zookeeper
- Then the receiver was restored
- The data that can be read from the WAL is re-consumed once because the kafka High-Level consumption API is used, starting from the offsets saved in zookeeper
WAL shortcomings
Through the above description, WAL has two shortcomings:
Reducing the performance of receivers, because the data should also be stored to HDFS and other distributed file system
For some resources, there may be duplicate data, such as Kafka, there is a data in Kafka, and there is a copy of the Spark Streaming (stored in the Hado API-compatible file system in the form of WAL)
Kafka direct API
For the loss of performance of WAL and exactly-once, spark streaming1.3 uses the Kafka direct API. Very clever, Spark driver to calculate the next batch offsets, directing executor consumption corresponding topics and partitions. Consuming Kafka news, just like consuming a file system file.
- No need kafka receivers, executor directly through the Kafka API consumption data
- WAL is no longer needed, and if you recover from failure, you can re-consume
- Exactly-once is guaranteed, no longer read data from WAL again
to sum up
Mainly to say that spark streaming through a variety of ways to ensure that the data is not lost, and ensure exactly-once, each version are spark streaming more and more stable, more and more to the production environment to use the development.
reference
Spark-streaming Recent Evolution of Zero Data Loss Guarantee in Spark Streaming With Kafka
Kafka direct API
Spark streaming
Original link: https://github.com/jacksu/utils4 ... / md / spark_streaming Use kafka to ensure data zero



Commentaires
Enregistrer un commentaire