Spark Streaming picture processing case introduction
Problem guide
1. What are the characteristics of streaming architecture frameworks?

Streaming framework features
Flow processing framework technology requirements



Spark Streaming
Spark Streaming application example
Listing 1. Loop the image file code
Listing 3. Scala implementation reads the file
Listing 4. Writing a file
Concluding remarks
1. What are the characteristics of streaming architecture frameworks?
2. What are the technical requirements for streaming processing frameworks?
3. How to read the image file through the Spark Streaming program based on the process into the data stream?
Streaming framework features
The main features of the flow management framework are the following five aspects.
1. Strong real-time processing
Stream processing needs to ensure real-time data generation, real-time
computing, in addition, also need to ensure that the results of
real-time transmission.
Most streaming processing architectures use memory calculations, that
is, when the data arrived directly after the calculation in memory, only
a small amount of data will be saved to the hard disk, or simply do not
save the data.
This system architecture ensures that we can provide low latency
computing capabilities that can be quickly calculated and calculated in a
short period of time to reflect the usefulness of the data. For data that is particularly short and the potential value is large, it can be given priority.
2. High fault tolerance
Because the data is easy to lose, it requires the system to have a
certain degree of fault tolerance, to make full use of the only one data
computing opportunities, as far as possible comprehensive, accurate and
effective from the data flow to obtain valuable information.
3. Dynamic change
Generally, the application scenario of the streaming architecture has
the situation that the data rate is not fixed, that is, there may be a
large difference between the data rate and the data rate at the previous
time.
This requirement requires that the system has good scalability, can
dynamically adapt to the incoming data stream, with strong system
computing power and large data traffic dynamic matching ability.
On the one hand, in the case of high data flow rates, it is ensured
that no data is discarded, or that some unimportant data is identified
and selectively discarded; on the other hand, in the case of low data
rates, Occupies system resources.
4. Multiple data sources
Because there may be a lot of data sources, and each data source, data
flow may be independent of each other, so there is no guarantee that the
data is orderly, which requires the system in the data calculation
process has a good data analysis and discovery The ability to rule, can
not rely too much on the intrinsic logic of the data flow or internal
logic within the data stream.
5. High scalable
As the data is generated in real time, the dynamic increase, that is,
as long as the data source is active, the data will continue to produce
and continue to increase. It can be said that the amount of potential data is infinite, can not use a specific data to achieve its quantification. The system can not save all data during the data calculation.
Because there is not enough space in the hardware to store these
infinite data, there is no suitable software to effectively manage so
much data.
Flow processing framework technology requirements
For ideal streaming applications with strong real-time processing, high
fault tolerance, dynamic change, multiple data sources, and high
scalability, then the ideal flow management framework should exhibit low
latency, high throughput, continuous and stable operation and
resiliency Scalability and other characteristics, which requires the
system design architecture, task execution, high availability technology
and other key technologies reasonable planning and good design.
- System design architecture
The system architecture is a combination of subsystems in the system,
and the streaming architecture needs to select a specific system
architecture for the deployment of streaming computing tasks.
Currently, the system architecture that is more popular for streaming
processing frameworks has a point-point architecture with no central
nodes and a Master-Slaves architecture with a central node.
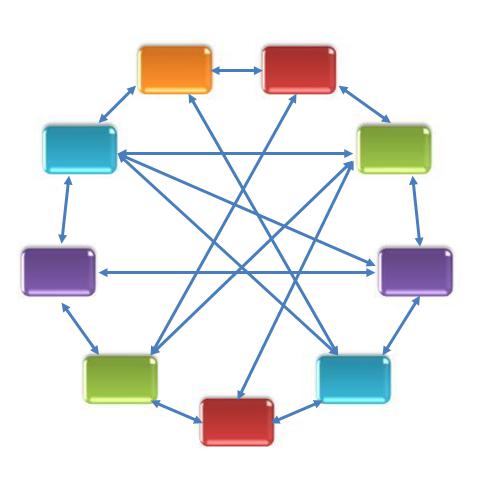
(1) symmetric architecture.
As shown in Figure 1, the role of each node in the system is exactly
the same, that is, all nodes can be done with each other backup, so that
the whole system has good scalability.
But because there is no central node, so in the resource scheduling,
system fault tolerance, load balancing and so on through the need for
distributed protocol to help achieve.
The current commercial products S4, Puma belong to this type of
architecture, S4 through Zookeeper system fault tolerance, load
balancing and other functions.
Figure 1. Centerless node architecture
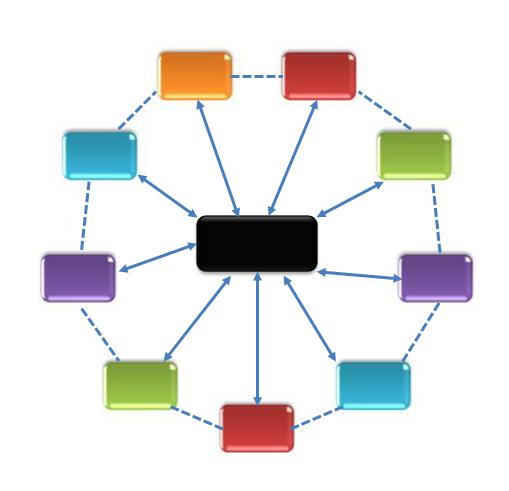
(2) master-slave system architecture. As shown in Figure 2, the system has a master node and multiple slave nodes.
The master node is responsible for the coordination of system resources
management and tasks, and completes the system fault tolerance, load
balancing and other aspects of the work, from the node responsible for
receiving the task from the main node, and after the completion of the
calculation feedback.
Each node can choose whether or not to communicate with each other, but
the overall operating state of the system depends on the master node
control. Storm, Spark Streaming belongs to this architecture.
Figure 2. Center node architecture
- Task execution mode
Task execution refers to the completion of the task map to the physical
computing node after the deployment of the various computing nodes
between the data transmission. The data transmission mode is divided into active push mode and passive pull mode.
(1) active push mode.
After the data is generated or calculated by the upstream node, the
data is sent to the corresponding downstream node. The essence is to let
the relevant data actively find the downstream computing node. When the
downstream node reports that the fault occurs or the load is too heavy,
the subsequent data stream is pushed To other corresponding nodes.
The advantage of active push mode is the initiative and timeliness of
data calculation. However, because the data is actively pushed to the
downstream node, it is often not too much to take into account the load
state and working status of the downstream node, which may lead to the
downstream node The load is not balanced;
(2) passive pull way.
Only the downstream node explicitly requests the data, the upstream
node will transfer the data to the downstream node, the essence of which
is to pass the relevant data passively to the downstream computing
node.
The advantage of the passive pull mode is that the downstream node can
request data according to its own load state and working state, but the
data of the upstream node may not be calculated in time.
Large data flow computing real-time requirements are higher, the data
need to be processed in a timely manner, often choose to actively push
the data transmission.
Of course, the active push mode and passive pull is not completely
opposite, but also can be the two fusion, so as to achieve a certain
degree of better results.
- High availability technology
The high availability of the streaming computing framework is achieved through stateful backup and failover policies. When the fault occurs, the system replays and restores the data according to a predefined policy.
According to the implementation strategy, can be divided into passive
waiting (passive standby), active standby (upstream) and upstream backup
(upstream backup) these three strategies.
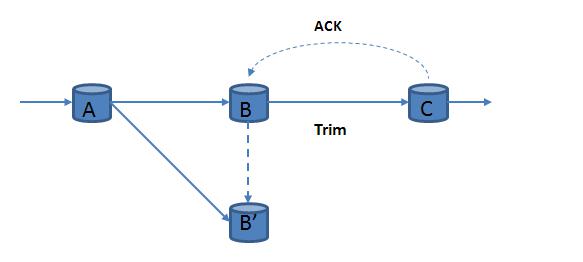
(1) Passive waiting strategy
As shown in Fig. 3, the master node B performs data calculation, and
the replica node B 'is in the standby state, and the system updates the
latest state on the master node B to the replica node B' periodically. In the event of a failure, the system performs state recovery from the backup data.
The passive wait policy supports scenarios with higher data load and
larger throughput, but the recovery time is longer, and the recovery
time can be shortened by the distributed storage of the backup data.
This approach is more suitable for accurate data recovery, can be very
good to support the application of uncertainty computing, flow data in
the current application of the most widely used.
Figure 3. Passive wait strategy
(2) active waiting strategy
As shown in Figure 4, the system transmits a copy of the data for the
replica node B 'while transmitting data for the master node B.
When the master node B fails, the replica node B 'takes over the work
of the master node B, and the primary and secondary nodes need to
allocate the same system resources. The way to recover the shortest time, but the data throughput is small, but also a waste of more system resources.
In the WAN environment, the system load is often not too large, the
active wait strategy is a better choice, you can in a relatively short
period of time to achieve system recovery.
Figure 4. Active waiting strategy
(3) upstream backup strategy
Each master node records its own status and output data to the log
file. When a master node B fails, the upstream master node replays the
data in the log file to the corresponding replica node B 'for
recalculation of the data The
The upstream backup policy takes up the least amount of system
resources. During the trouble-free period, the data execution efficiency
is high because the replica node B 'is idle.
But because of its need for a long time to restore the state of
recovery, fault recovery time is often longer, such as the need to
restore the time window for the 30-minute clustering calculation, you
need to replay the 30 minutes of all tuples.
It can be seen that the upstream backup strategy is a better choice
when the system resources are scarce and the operator state is less. As shown in Figure 5 and Figure 6.
Figure 5. Upstream backup policy 1
Figure 6. Upstream backup policy 2
Spark Streaming
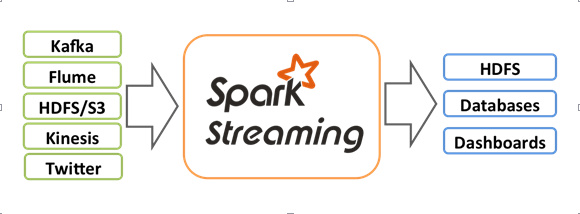
Spark Streaming is an extension of Spark, dedicated to streaming data processing. Spark Streaming supports Kafka, Flume, Twitter, ZeroMQ, Kinesis, TCP Sockets and other data sources. In addition, you can use a complex algorithm, such as map, reduce, join, window, these to deal with data. The processed data can be sent to the file system, the database, and other third parties. Figure 7 quoted from the Spark Streaming official website, a better description of the status of Spark Streaming.
Figure 7. Spark Streaming status
Spark Streaming receives the output data stream, then divides the data
into batches, and the Spark engine processes the data later, eventually
generating the results and sending them to the external system.
The author of the previous article has been detailed through the
WordCount example describes the Spark Streaming run order, the basic
structure, RDD concept, please refer to the article "Spark Streaming
novice guide".
Spark Streaming application example
We take an example of a streaming image as an example of this article.
We read the image file through the Spark Streaming program based on the
program to read into the data stream, re-write the data stream as a
picture file and stored on the file system.
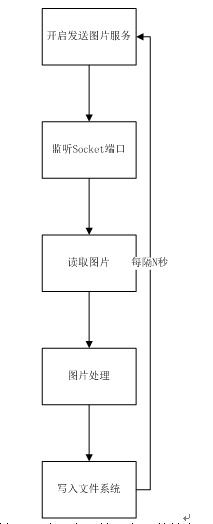
The flow chart of the whole program is shown in Figure 8.
Figure 8. Picture processing program flow chart
As shown in Figure 8, the first step we need to implement a service,
the service kept to the HDFS file system to write image files, these
image files will be used as a data source of the original data, and be
processed The The code is shown in Listing 1.
Listing 1. Loop the image file code
[Java] plain text view copy code
Public ServerSocket getServerSocket (int port) { ServerSocket server = null; Try { Server = new ServerSocket (); } Catch (IOException e) { // TODO Auto-generated catch block E.printStackTrace (); } Return server } Public void sendData (String path, ServerSocket server) { OutputStream out = null; FileInputStream in = null; BufferedOutputStream bf = null; Try { Out = server.accept (). GetOutputStream (); File file = new File (path); In = new FileInputStream (file); Bf = new BufferedOutputStream (out); Byte [] bt = new byte [(int) file.length ()]; In.read (bt); Bf.write (bt); } Catch (IOException e) { E.printStackTrace (); } Finally { If (in! = Null) { Try { In.close (); } Catch (IOException e) { // TODO Auto-generated catch block E.printStackTrace (); } } If (bf! = Null) { Try { Bf.close (); } Catch (IOException e) { // TODO Auto-generated catch block E.printStackTrace (); } } If (out! = Null) { Try { Out.close (); } Catch (IOException e) { // TODO Auto-generated catch block E.printStackTrace (); } } If (! Server.isClosed ()) { Try { Server.close (); } Catch (IOException e) { // TODO Auto-generated catch block E.printStackTrace (); } } } } Public static void main (String [] args) { If (args.length <4) { System.err.println ("Usage: server3 <port> <file or dir> <send-times> <sleep-time (ms)>"); System.exit (1); } Map <Integer, String> fileMap = null; Server s = new Server (); For (int i = 0; i <Integer.parseInt (args [2]); i ++) { ServerSocket server = null; While (server == null) { Server = s.getServerSocket (Integer.parseInt (args [0])); Try { Thread.sleep (Integer.parseInt (args [3])); } Catch (InterruptedException e) { // TODO Auto-generated catch block E.printStackTrace () } } While (! Server.isBound ()) { Try { Server.bind (new InetSocketAddress (Integer.parseInt (args [0]))); System.out.println ("+" (i + 1) + "server-side binding successful"); Thread.sleep (Integer.parseInt (args [3])); } Catch (NumberFormatException | IOException | InterruptedException e) { // TODO Auto-generated catch block E.printStackTrace (); } } FileMap = s.getFileMap (args [1]); System.out.println ("fileMap.size =" + fileMap.size ()); //System.out.println("fileMap="+fileMap); S.sendData (fileMap.get (s.getNum (0, fileMap.size () - 1)), server); //s.sendData(args[1], server); } } Public Map <Integer, String> getMap (String dir, Map <Integer, String> fileMap) { File file = new File (dir); If (file.isFile ()) { If (file.getName (). EndsWith (". Jpg") || file.getName (). EndsWith (". Bmp") | file.getName (). EndsWith (". JPG") || file.getName (). EndsWith (".BMP")) { If (file.length () <1024 * 1024 * 2) { FileMap.put (fileMap.size (), file.getAbsolutePath ()); } } Else { } } If (file.isDirectory ()) { File [] files = file.listFiles (); For (int j = 0; j <files.length; j ++) { GetMap (files [j] .getAbsolutePath (), fileMap); } } Return fileMap; } Public Map <Integer, String> getFileMap (String dir) { Map <Integer, String> fileMap = new HashMap <Integer, String> (); Return getMap (dir, fileMap); } Public int getNum (int offset, int max) { Int i = offset + (int) (Math.random () * max); If (i> max) { Return i-offset; } Else { Return i; } }
Then open a program to achieve open Socket monitoring, from the
specified port to read the picture file, here is the Spark Streaming
socketStream method to obtain data flow. The program code is written in Scala language, as shown in Listing 4.
Listing 2. Reading the file
[JavaScript] plain text view copy code
Val s = new SparkConf (). SetAppName ("face") Val sc = new SparkContext (s) Val ssc = new StreamingContext (sc, Seconds (args (0) .toInt)) Val img = new ImageInputDStream (ssc, args (1), args (2) .toInt, StorageLevel.MEMORY_AND_DISK_SER) // call the rewritten ImageInputDStream method to read the image val imgMap = img.map (x => (new Text (System.currentTimeMillis (). ToString), x)) ImgMap.saveAsNewAPIHadoopFiles ("hdfs: // spark: 9000 / image / receiver / img", "", classOf [Text], ClassOf [BytesWritable], classOf [ImageFileOutputFormat], Ssc.sparkContext.hadoopConfiguration) // call the ImageFileOutputFormat method to write the image imgMap.map (x => (x._1, { If (x._2.getLength> 0) imageModel (x._2) else "-1" })) // Get the value of key, ie the image .filter (x => x._2! = "0" && x._2! = "-1") (X => "{time:" + x._1.toString + "," + x._2 + "},"). Print () Ssc.start () Ssc.awaitTermination ()
Listing 2 sets the Spark context, sets how many times (the first
parameter entered by the user, in seconds) to read the data source, and
then starts calling the rewrite method to read the picture. We need to
analyze the image , The analysis process is not the focus of this
procedure, here ignored, the reader can search their own online image
analysis of the open source library, import can be achieved image
analysis.
Listing 3 which defines a Scala class ImageInputDStream, used to load Java read the picture class.
Listing 3. Scala implementation reads the file
[Java] plain text view copy code
Class ImageInputDStream (@transient ssc_: StreamingContext, host: String, port: Int, storageLevel: StorageLevel) extends ReceiverInputDStream [BytesWritable] (ssc_) with Logging { Override def getReceiver (): Receiver [BytesWritable] = { New ImageRecevier (host, port, storageLevel) } } Class ImageRecevier (host: String, port: Int, storageLevel: StorageLevel) extends Receiver [BytesWritable] (storageLevel) with Logging { Override def onStart (): Unit = { New Thread ("Image Socket") { SetDaemon (true) Override def run (): Unit = { Receive () } } .start () } Override def onStop (): Unit = { } Def receive (): Unit = { Var socket: Socket = null Var in: InputStream = null Try { LogInfo ("Connecting to" + host + ":" + port) Socket = new Socket (host, port) LogInfo ("Connected to" + host + ":" + port) In = socket.getInputStream Val buf = new ArrayBuffer [Byte] () Var bytes = new Array [Byte] (1024) Var len = 0 While (-1 <len) { Len = in.read (bytes) If (len> 0) { Buf ++ = bytes } } Val bw = new BytesWritable (buf.toArray) LogError ("byte :::::" + bw.getLength) Store (bw) LogInfo ("Stopped receiving") Restart ("Retrying connecting to" + host + ":" + port) } Catch { Case e: java.net.ConnectException => Restart ("Error connecting to" + host + ":" + port, e) Case t: Throwable => Restart ("Error receiving data", t) } Finally { If (in! = Null) { In.close () } If (socket! = Null) { Socket.close () LogInfo ("Closed socket to" + host + ":" + port) } } }
Listing 2 defines the need to call ImageFileOutputFormat when writing
back to the image file. This class inherits the
org.apache.hadoop.mapreduce.lib.output.FileOutputFormat class, which
speeds up the data read by buffering. The code is shown in Listing 4.
Listing 4. Writing a file
[Java] plain text view copy code
Public class ImageFileOutFormat extends FileOutputFormat <Text, BytesWritable> { @Override Public RecordWriter <Text, BytesWritable> getRecordWriter (TaskAttemptContext taskAttemptContext) Throws IOException, InterruptedException { Configuration configuration = taskAttemptContext.getConfiguration (); Path path = getDefaultWorkFile (taskAttemptContext, ""); FileSystem fileSystem = path.getFileSystem (configuration); FSDataOutputStream out = fileSystem.create (path, false); Return new ImageFileRecordWriter (out); } Protected class ImageFileRecordWriter extends RecordWriter <Text, BytesWritable> { Protected DataOutputStream out; Private final byte [] keyValueSeparator; Private static final String colon = ","; Public ImageFileRecordWriter (DataOutputStream out) { This (colon, out); } Public ImageFileRecordWriter (String keyValueSeparator, DataOutputStream out) { This.out = out; This.keyValueSeparator = keyValueSeparator.getBytes (); } @Override Public void write (Text text, BytesWritable bytesWritable) throws IOException, InterruptedException { If (bytesWritable! = Null) { Out.write (bytesWritable.getBytes ()); } } @Override Public void close (TaskAttemptContext taskAttemptContext) throws IOException, InterruptedException { Out.close (); } } }
Through the program in Listing 1-4, we can read the picture file ->
the business of some of the pictures -> write back the analysis of
the results (text information, pictures).
Concluding remarks
Through this study, the reader can understand the design principle of
the flow processing framework, the working principle of Spark Streaming,
and help the reader to deepen the understanding through an example of
reading, analyzing and writing pictures.
Currently available on the market Spark Chinese books for beginners are
mostly more difficult to read, but no specifically for Spark Streaming
article.
The author seeks to introduce a series of Spark articles, so that
readers can start from the perspective of practical understanding of
Spark Streaming.
Follow-up in addition to the application of the article, but also
committed to Spark and Spark Streaming based on the system architecture,
source code interpretation and other aspects of the article published.



Commentaires
Enregistrer un commentaire